- 为什么要学习系统设计? Why should I learn system design?
- 什么是系统设计? What is System Design?
- 系统设计基础 System Design fundamentals
- 水平和垂直缩放 Horizontal and vertical scaling
- 微服务 Microservices
- 代理服务器 Proxy servers
- CAP定理 CAP theorem
- 冗余和复制 Redundancy and replication
- 存储 Storage
- 消息队列 Message queues
- 文件系统 File systems
- 系统设计模式 System Design patterns
- 数据库 Databases
- 什么是分布式系统? What are distributed systems?
- 分布式系统故障 Distributed system failures
- 分布式系统基础知识 Distributed system fundamentals
- 分布式系统设计模式 Distributed system design patterns
- 可扩展的网络应用程序 Scalable web applications
- 机器学习和系统设计 Machine learning and System Design
- 容器化和系统设计 Containerization and System Design
- 云和系统设计 The Cloud and System Design
为什么要学习系统设计? Why should I learn system design?
在过去的二十年里,大型Web应用程序取得了很多进步。这些进步重新定义了我们思考软件开发的方式。我们每天使用的所有应用程序和服务,如Facebook,Instagram和Twitter,都是可扩展的系统。全世界有数十亿人同时访问这些系统,因此它们需要设计为处理大量流量和数据。这就是系统设计的用武之地。
作为一名软件开发人员,你将越来越多地被要求理解系统设计概念以及如何应用它们。在你职业生涯的早期阶段,学习系统设计将使你更有信心地解决软件设计问题,并将设计原则应用到日常工作中。当你在职业生涯中取得进步,开始面试更高级别的职位时,系统设计将成为你面试过程中更大的一部分。因此,无论您的级别是什么,系统设计对您都很重要。
由于其日益重要,我们希望创建一个资源来帮助您浏览系统设计的世界。本指南详细介绍了系统设计的基本概念,并将您链接到相关资源,以帮助您获得更深入的理解并获得实际操作经验。
系统设计的用武之地:处理数以亿计的大量流量和数据
什么是系统设计? What is System Design?
系统设计是为满足特定需求的系统定义体系结构、接口和数据的过程。系统设计通过连贯和高效的系统满足您的业务或组织的需求。一旦您的企业或组织确定了其需求,您就可以开始将其构建到满足客户需求的物理系统设计中。您设计系统的方式将取决于您是否想进行定制开发、商业解决方案或两者的组合。
系统设计需要系统的方法来构建和工程系统。一个好的系统设计需要考虑基础设施中的所有内容,从硬件和软件,一直到数据及其存储方式。
HOW? 设计系统的方式:定制开发、商业解决方案或两者的组合
WHAT? 设计系统的内容:从硬件和软件,一直到数据及其存储方式
系统设计基础 System Design fundamentals
水平和垂直缩放 Horizontal and vertical scaling
可伸缩性是指应用程序在不牺牲延迟的情况下处理和承受增加的工作负载的能力。应用程序需要强大的计算能力才能很好地扩展。服务器应该足够强大,以处理增加的流量负载。有两种主要的方法来扩展应用程序:水平和垂直。
水平扩展或横向扩展意味着向现有硬件资源池添加更多硬件。它增加了整个系统的计算能力。垂直扩展或向上扩展意味着为您的服务器添加更多功能。它增加了运行应用程序的硬件的能力。
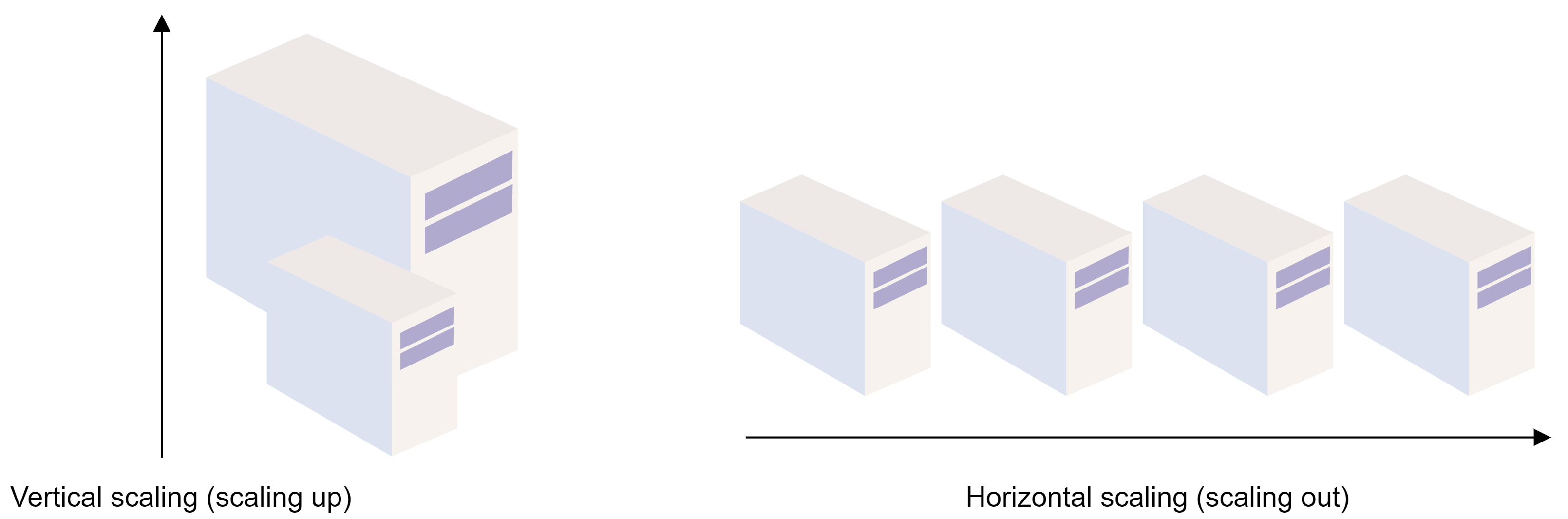
这两种缩放方式各有利弊。您将遇到需要考虑权衡并决定哪种类型的扩展最适合您的用例的场景。
水平扩展:硬件资源扩展配置
垂直扩展:添加服务器资源数量
微服务 Microservices
微服务或微服务架构是一种架构风格,使用松散耦合的服务构建应用程序。它将大型应用程序划分为一组独立的模块化服务。这些模块可以独立开发、部署和维护。
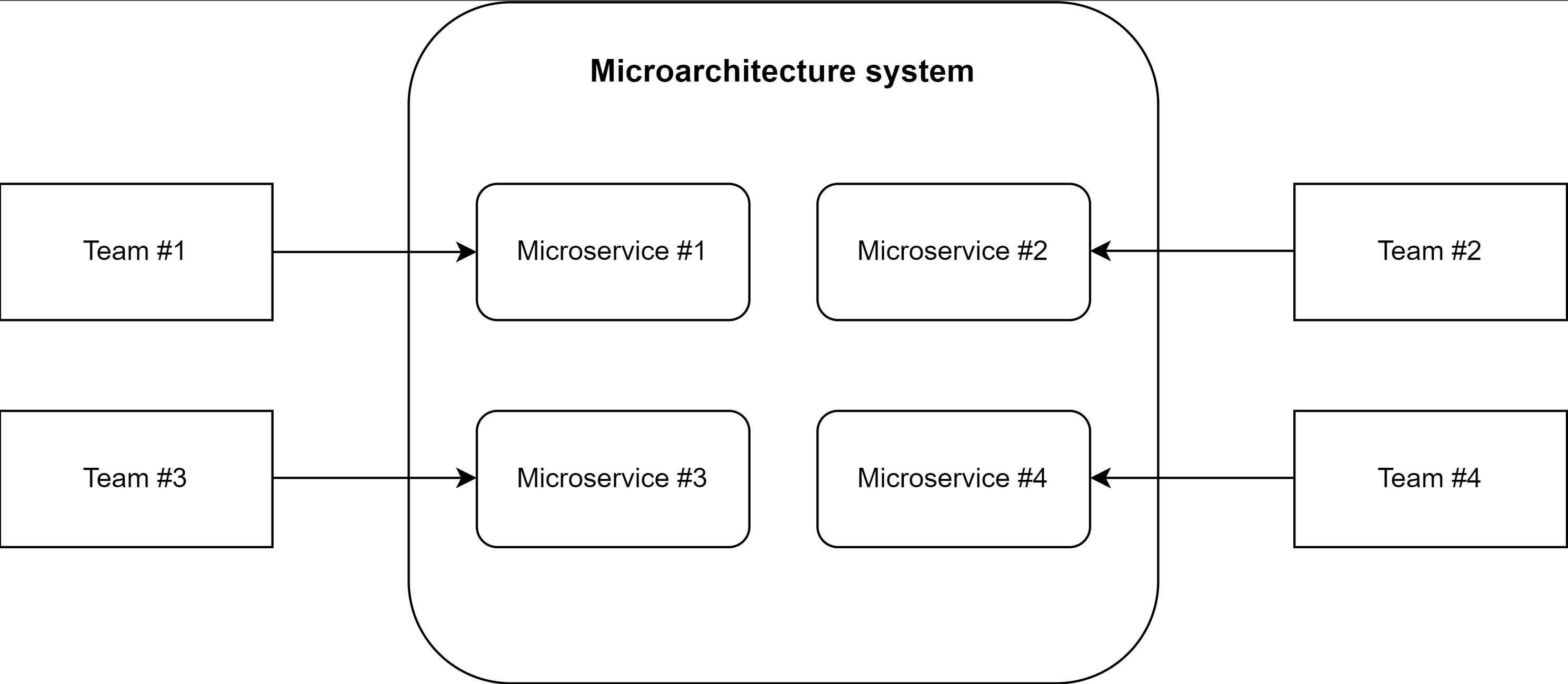
在微架构系统中,每个微服务都有一个团队在工作。
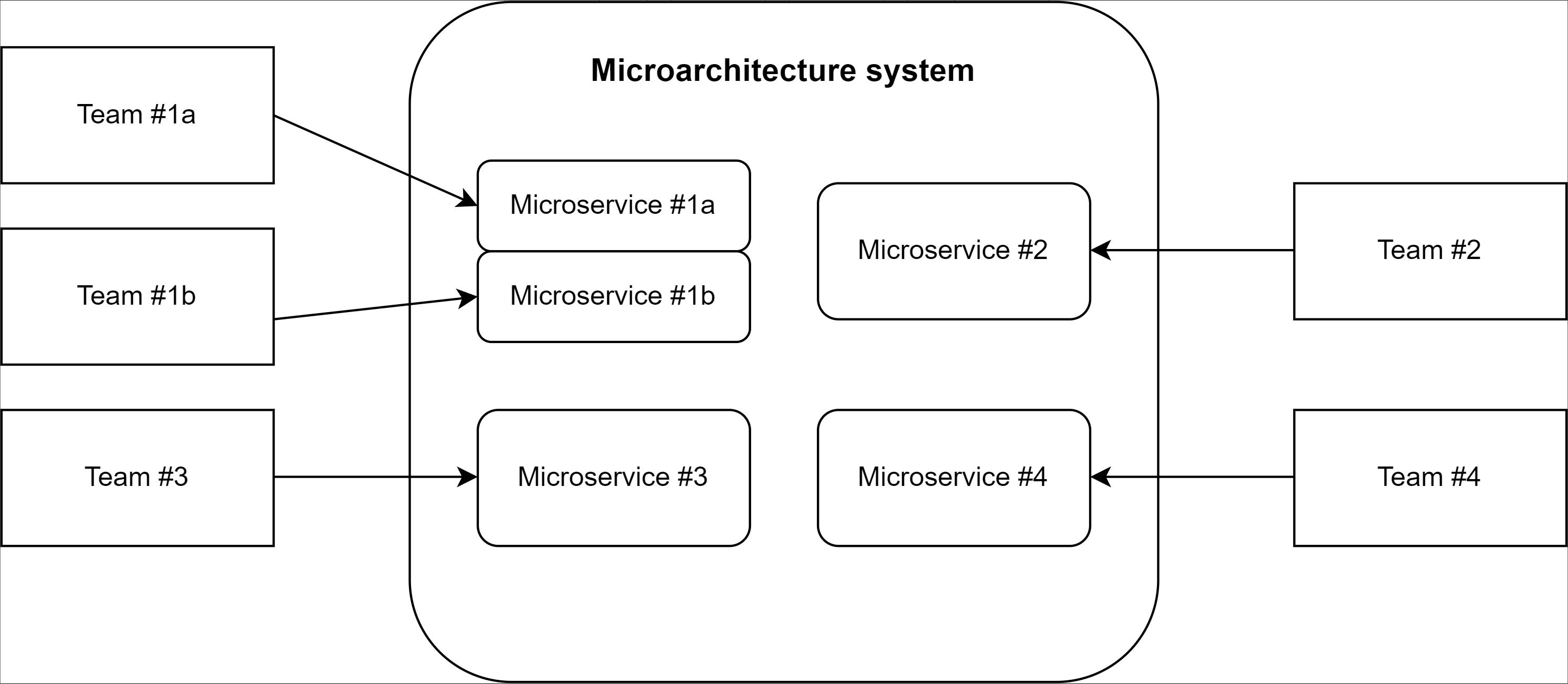
随着团队#1的增长超过了单个微服务的限制,我们可以轻松地扩展微服务以满足团队不断变化的需求。
微服务的运行速度比传统的单片应用程序快得多,也更可靠。由于应用程序被分解为独立的服务,每个服务都有自己的逻辑和代码库。这些服务可以通过应用程序编程接口(API)相互通信。
如果你想开发一个更具可扩展性的应用程序,微服务是理想的选择。使用微服务,由于其现代功能和模块,扩展应用程序要容易得多。如果您与大型或不断增长的组织合作,微服务对您的团队非常有用,因为它们更容易随着时间的推移进行扩展和自定义。
代理服务器 Proxy servers
代理服务器或转发代理充当用户和Internet之间的通道。它将最终用户与他们正在浏览的网站分开。代理服务器不仅转发用户请求,还提供许多好处,例如:
- 改进的安全性
- 改善隐私
- 访问被阻止的资源
- 控制员工和儿童的互联网使用
- 缓存数据以加速请求
每当用户从终端服务器发送一个地址请求时,流量在到达该地址的途中会流经代理服务器。当请求返回到用户时,它通过同一代理服务器流回,然后将其转发给用户。
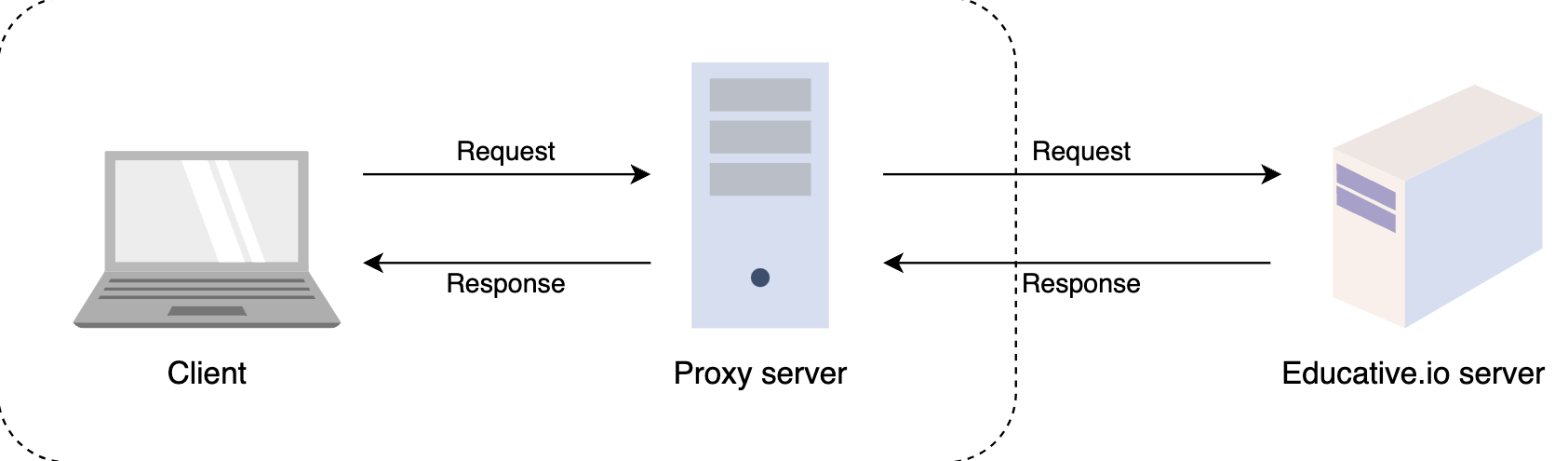
转发代理
正向代理:VPN
CAP定理 CAP theorem
CAP定理是系统设计领域中的一个基本定理。它指出分布式系统只能同时提供三个属性中的两个:一致性、可用性和分区容限。该定理形式化了存在分区时一致性和可用性之间的权衡。
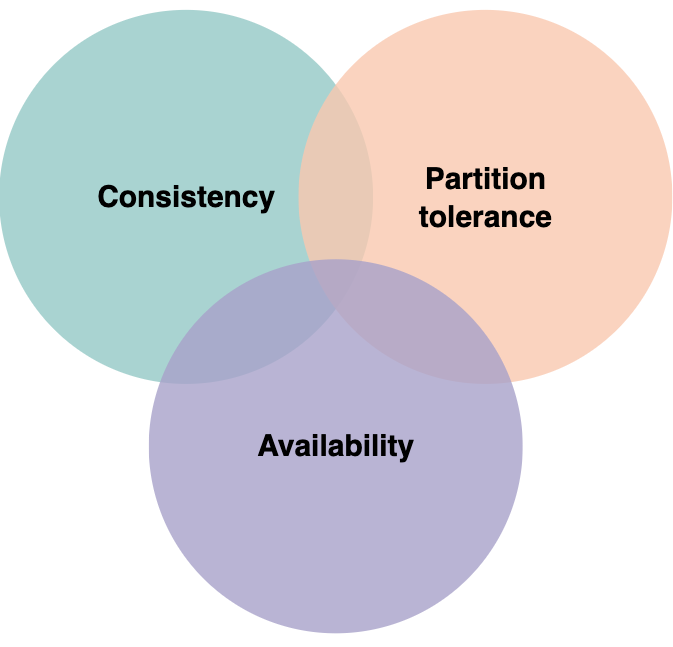
CAP理论
【CA】满足ACID理论,例如传统的关系型数据库:MySQL、Oracle
【AP】保证可用性 & 分区容错性,不要求实时的一致性,例如:ES
【CP】满足BASE理论,例如基于Raft分布式系统协议,选举过程是不可用的:Redis
延伸:BASE理论,CAP理论的放松版本
【BA】基本可用
【S】软状态,系统可能会处于一种中间状态,系统允许短暂的不一致性
【E】最终一致性
【核心思想】 即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
冗余和复制 Redundancy and replication
冗余是复制系统的关键组件的过程,目的是提高系统的可靠性或整体性能。它通常以备份或故障安全的形式出现。冗余在消除系统中的单点故障并在需要时提供备份方面发挥着关键作用。例如,如果我们在生产环境中运行一个服务的两个实例,其中一个实例失败了,系统可以故障转移到另一个实例。
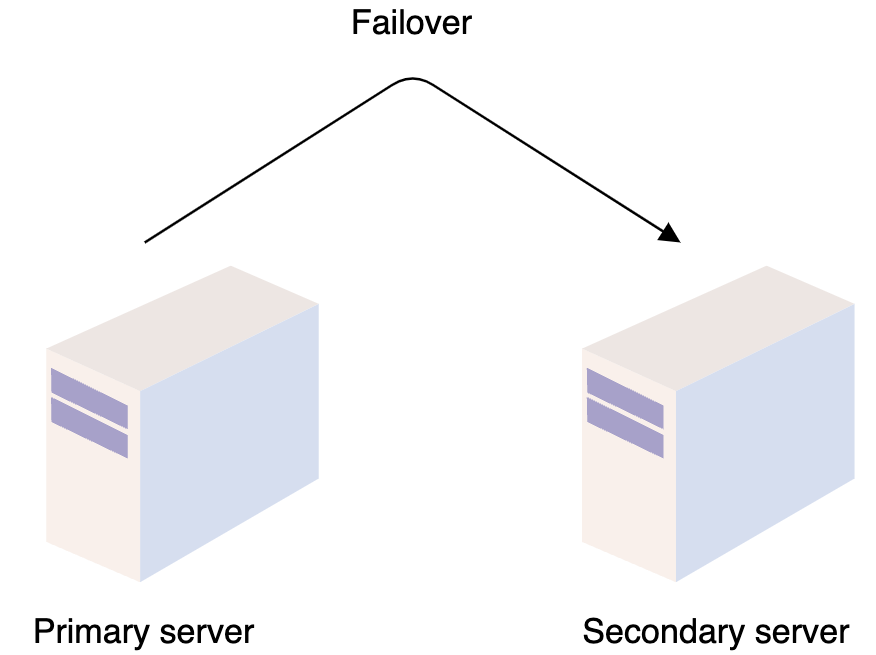
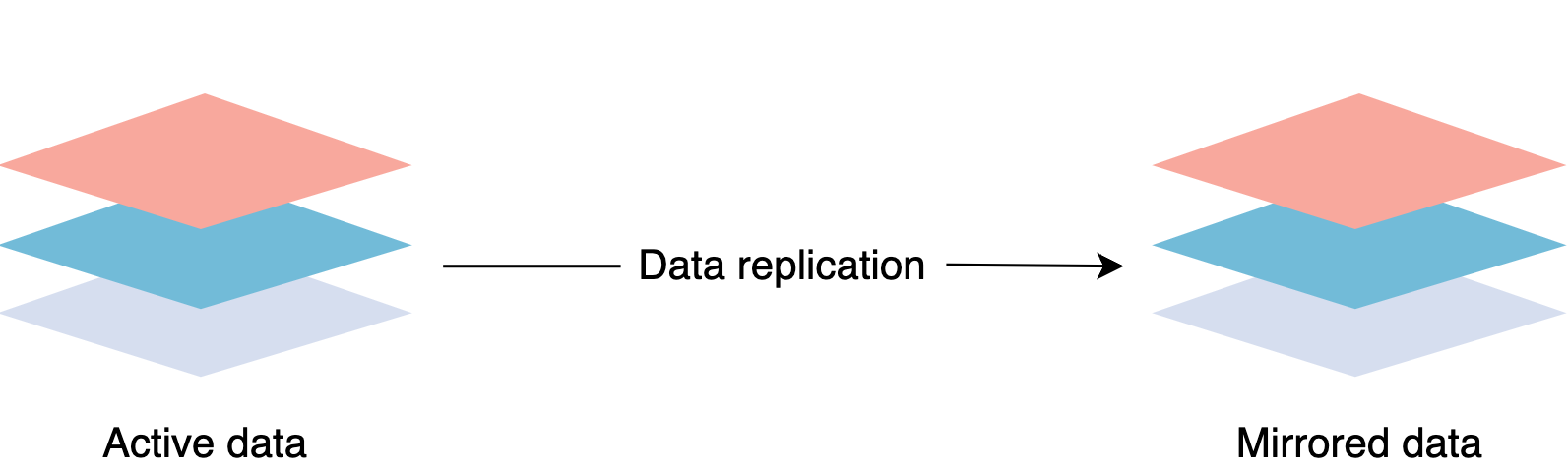
复制是共享信息以确保冗余资源之间的一致性的过程。您可以复制软件或硬件组件以提高可靠性、容错性或可访问性。复制在许多数据库管理系统(DBMS)中使用,通常在原始数据库和其副本之间具有主副本关系。主服务器接收所有更新,这些更新通过副本服务器传递。每个副本服务器在成功接收到更新时都会输出一条消息。
存储 Storage
数据是每个系统的核心。在设计系统时,我们需要考虑如何存储数据。我们可以根据系统的需要实现各种存储技术。
块存储 Block storage
块存储是一种数据存储技术,其中数据被分解为大小相等的块,并且每个单独的块都被赋予一个唯一的标识符以便于访问。这些块存储在物理存储中。与遵循固定路径相反,块可以存储在系统中的任何位置,从而更有效地利用资源。
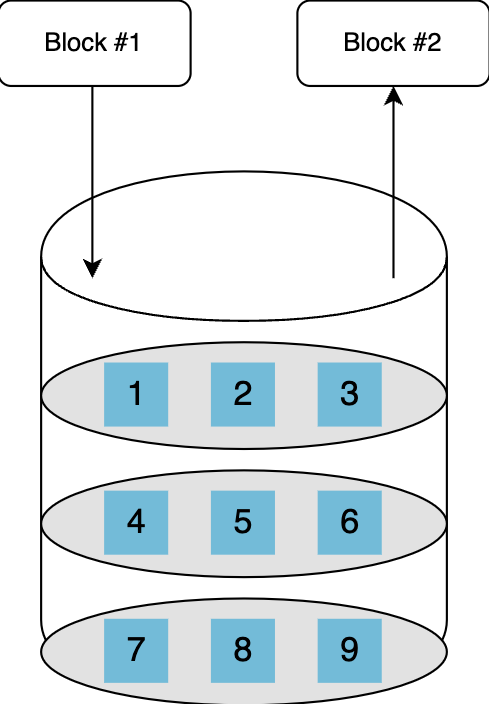
特定位置的固定大小块
适用场景:块存储适用于需要高性能、低延迟的数据存储场景,如数据库、事务处理等。
文件存储 File Storage
文件存储是一种分层存储方法。使用这种方法,数据存储在文件中。文件存储在文件夹中,然后存储在目录中。这种存储方法只适用于有限数量的数据,主要是结构化数据。
随着数据的大小增长到一定程度,这种数据存储方法可能会变得麻烦。
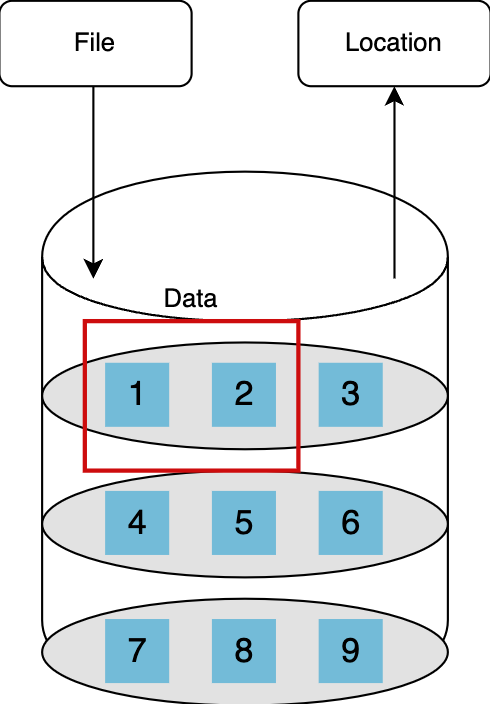
以固定的逻辑顺序排列的特定文件夹
适用场景:适用于非结构化数据存储存储场景,如云盘、云文件存储等。
个人文件系统:https://hyiki.sbs/dist/
对象存储 Object storage
对象存储是设计用于处理大量非结构化数据的存储。对象存储是数据归档和数据备份的首选数据存储方法,因为它提供了动态可伸缩性。操作系统不能直接访问对象存储。通信通过应用程序级别的RESTful API进行。这种类型的存储为系统提供了巨大的灵活性和价值,因为备份、非结构化数据和日志文件对任何系统都很重要。如果您正在设计一个具有大型数据集的系统,那么对象存储将非常适合您的组织。
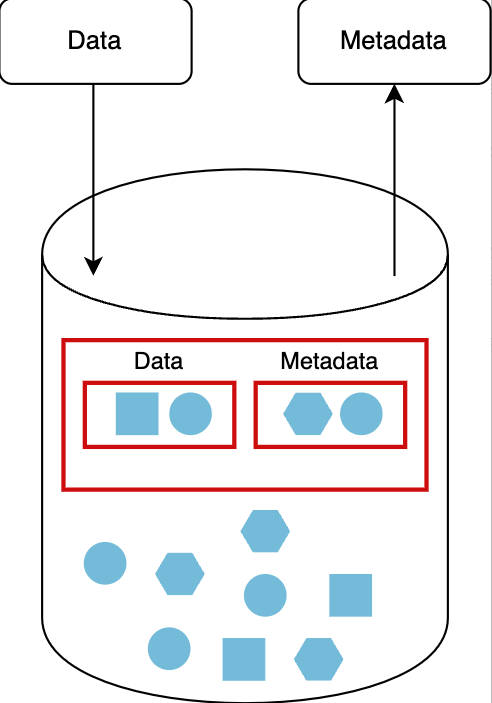
由元数据驱动的可扩展存储
适用场景:备份、非结构化数据和日志文件,例如阿里云OSS、Amazon S3对象存储系统
硬盘冗余阵列 Redundant Disk Arrays (RAID)
廉价磁盘冗余阵列(RAID)是一种使用多个磁盘协同构建更快、更大、更可靠的磁盘系统的技术。从外部看,RAID看起来像磁盘。在内部,它是一个复杂的工具,由多个磁盘、内存和一个或多个处理器组成,用于管理系统。硬件RAID类似于计算机系统,但专门用于管理一组磁盘的任务。有不同级别的RAID,它们都提供不同的功能。当设计一个复杂的系统时,你可能想要实现RAID存储技术。
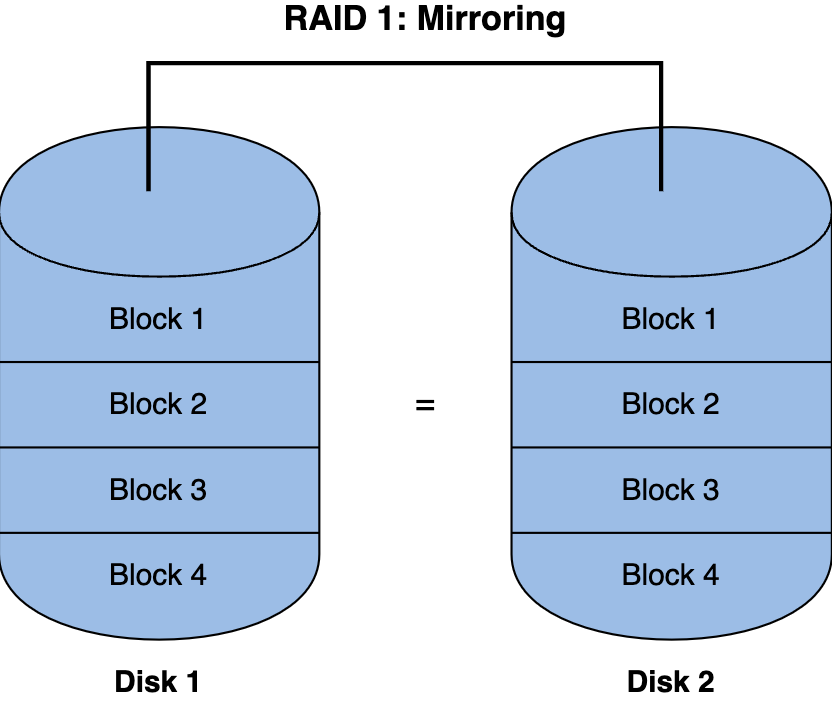
RAID 1技术:镜像
适用场景:数据冗余提高数据的安全性,例如NAS、监控、大型企业资源等场景
消息队列 Message queues
消息队列是将消息从源路由到目的地或从发送方路由到接收方的队列。它遵循FIFO(先进先出)政策。首先发送的消息将首先传递。消息队列促进了异步行为,这允许模块在后台相互通信,而不会妨碍主要任务。它们还促进了跨模块通信,并为消息提供临时存储,直到消费者处理和消费它们。
Kafka
Apache Kafka于2011年作为LinkedIn的消息传递系统开始,但后来发展成为一个流行的分布式事件流平台。该平台每天能够处理数万亿条记录。Kafka是一个分布式系统,由通过TCP网络协议通信的服务器和客户端组成。系统允许我们读取、写入、存储和处理事件。Kafka主要用于构建数据管道和实现流解决方案。
Kafka最初是由LinkedIn开发并开源的,设计初衷是处理大数据量的日志,后来因其高吞吐量和低延迟的特点,在实时数据处理领域得到广泛应用。
基本功能
- 高吞吐量:具有非常高的吞吐量和低延迟,可以轻松处理每秒数百万条消息。
- 分布式:是一个分布式的系统,可以通过增加服务器来提高容量和可用性。
- 消息可靠性:支持副本机制,可以确保消息在发送时不会丢失,并且可以通过多个副本来保证消息的可靠性。
- 多样化的使用场景:可用于日志收集、实时数据处理、消息系统、以及流处理等场景。
优劣势
- 优势
- 高吞吐量和低延迟,适合实时数据处理和大数据场景。
- 分布式系统,易于扩展。
- 消息可靠性高,支持副本机制。
- 劣势
- 学习成本高,需要深入理解其底层原理和实现细节。
- 部署复杂,对于初学者而言比较困难。
- 功能相对简单,缺乏一些高级功能和管理工具,但可以通过插件和集成其他系统来弥补。
RocketMQ
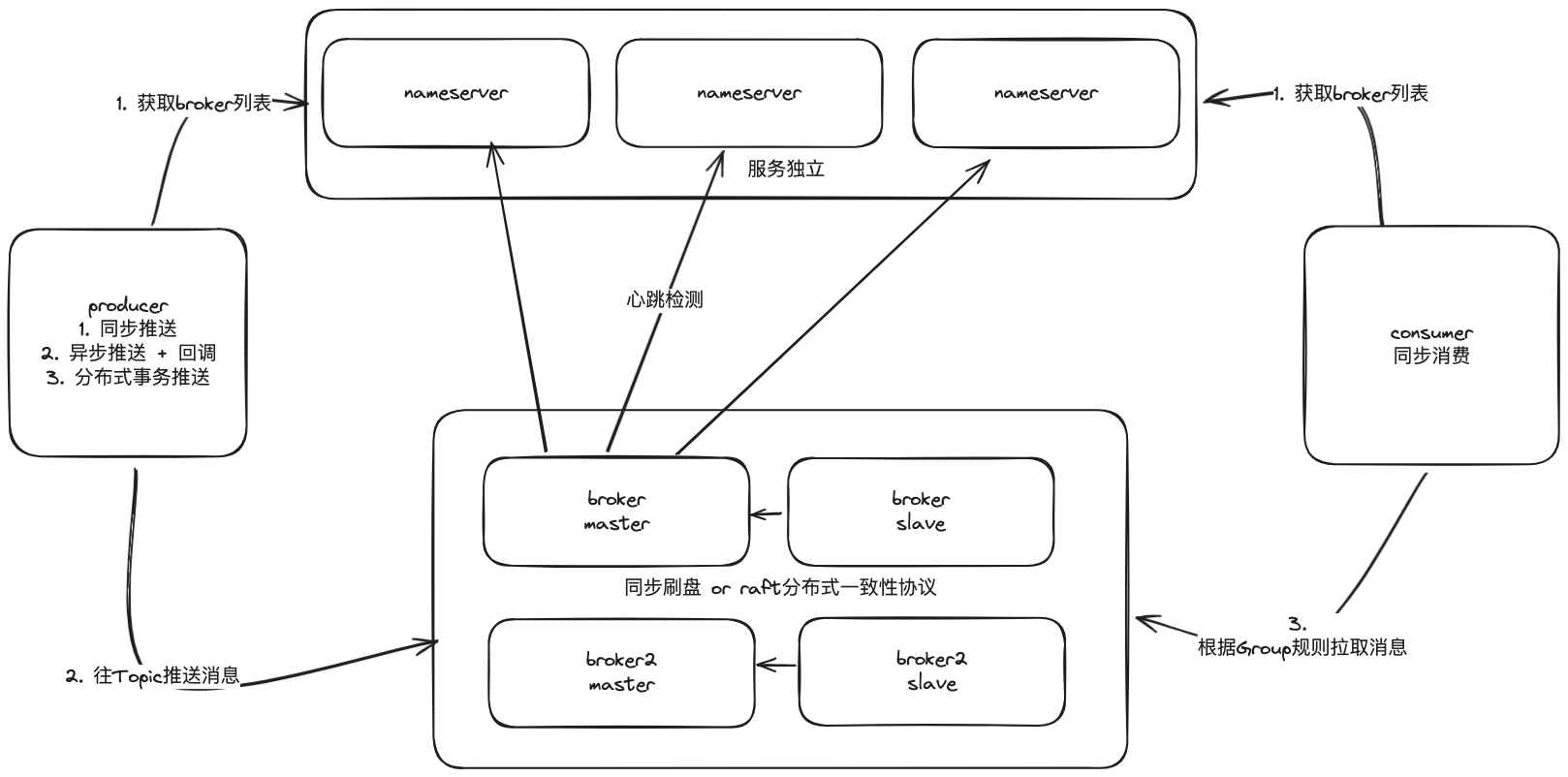
RocketMQ是阿里巴巴开源的分布式消息中间件,设计初衷是应对电商、金融等场景下的高并发、高性能和高可靠性的需求,如双十一等大规模促销活动。
基本功能
- 高可用性:支持集群模式,可以轻松实现高可用性。
- 易于使用:提供了易于使用的API,支持多种编程语言。
- 可扩展性:支持简单的水平扩展,可以通过添加新的broker节点来提高容量和可用性。
- 支持高级功能:如顺序消息、事务消息、定时消息等。
优劣势
- 优势
- 高性能和高吞吐量,适合大规模消息处理场景。
- 支持多种高级功能,如顺序消息、事务消息。
- 集群和HA实现相对简单,消息丢失率低。
- 提供丰富的监控和管理工具。
- 劣势
- 与Kafka相比,性能相对较弱。
- 社区生态相对较弱,但近年来逐渐增强。
文件系统 File systems
文件系统是管理存储磁盘上的数据存储方式和位置的进程。它管理存储磁盘的内部操作,并解释用户或应用程序如何访问磁盘数据。文件系统管理多个操作,例如:
- File naming 文件命名
- Storage management 存储管理
- Directories 目录
- Folders 文件夹
- Access rules 访问规则
如果没有文件系统,将很难识别文件、检索文件或管理单个文件的授权。
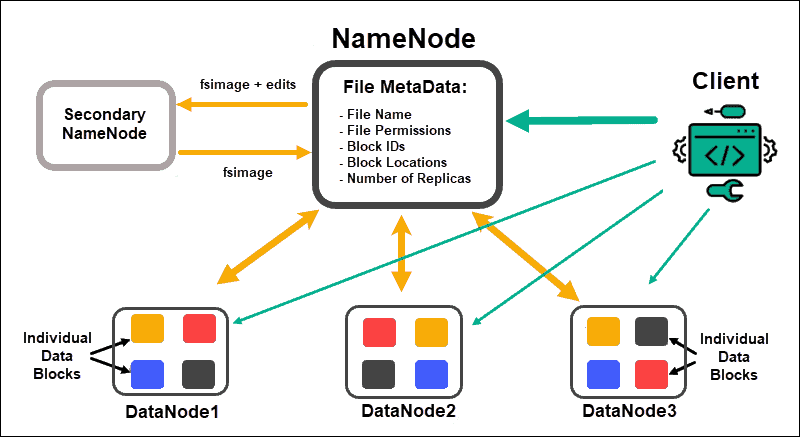
Google文件系统 Google File System (GFS)
Google文件系统(GFS)是一个可扩展的分布式文件系统,专为Gmail或YouTube等大型数据密集型应用程序设计。它被构建来处理大型数据集的批处理。GFS是为系统到系统的交互而设计的,而不是用户到用户的交互。它具有可扩展性和容错性。该架构由GFS集群组成,其中包含一个主服务器和多个可由多个客户端访问的ChunkServer。
Hadoop分布式文件系统 Hadoop Distributed File System (HDFS)
Hadoop分布式文件系统(HDFS)是一种分布式文件系统,可处理大型数据集并在商用硬件上运行。它旨在存储非结构化数据。HDFS是GFS的更简化版本。它的许多架构决策都受到GFS设计的启发。HDFS是围绕最有效的数据处理模式是“写一次,读多次”模式的想法构建的。
系统设计模式 System Design patterns
了解系统设计模式非常重要,因为它们可以应用于所有类型的分布式系统。他们也在系统设计面试中发挥重要作用。系统设计模式是指与分布式系统相关的常见设计问题及其解决方案。让我们来看看一些常用的模式。
布隆过滤器 Bloom filters
布隆过滤器是一种概率数据结构,旨在回答集合成员问题:这个元素是否存在于集合中?
布隆过滤器具有很高的空间效率,并且不存储实际的项。它们确定某个项是否不存在于集合中,或者某个项是否可能存在于集合中。他们不能判断一个项目是否肯定存在于一个集合中。空布隆过滤器是所有位都设置为零的位向量。在下图中,每个单元格代表一个位。位下面的数字是它在10位向量中的索引。
一致性哈希 Consistent hashing
一致性哈希将数据映射到物理节点,并确保在添加或删除服务器时只有一小部分密钥移动。一致性哈希将分布式系统管理的数据存储在一个环中。环中的每个节点都被分配了一个数据范围。这个概念在分布式系统中很重要,并且与数据分区和数据复制密切相关。一致性哈希也出现在系统设计面试中。
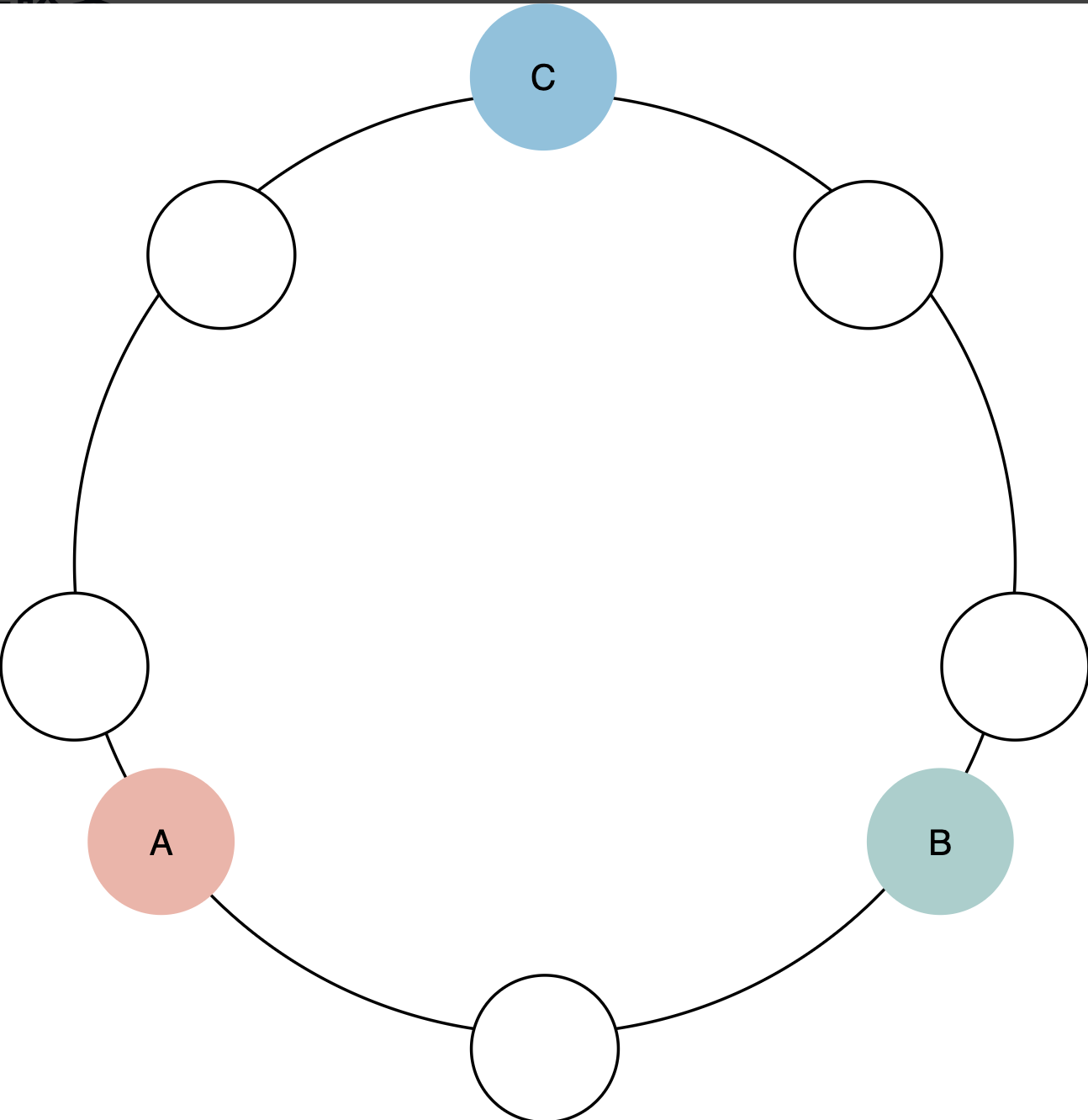
一致性哈希是一种有效的策略,可以解决分布式系统中的数据分片和负载均衡问题。它能够将数据均匀地分布到多个节点上,并确保节点变化时数据迁移的最小化,提高系统的可扩展性和容错性。
法定人数 Quorum
法定数量是在声明操作总体成功之前需要成功执行分布式操作的最小服务器数量。
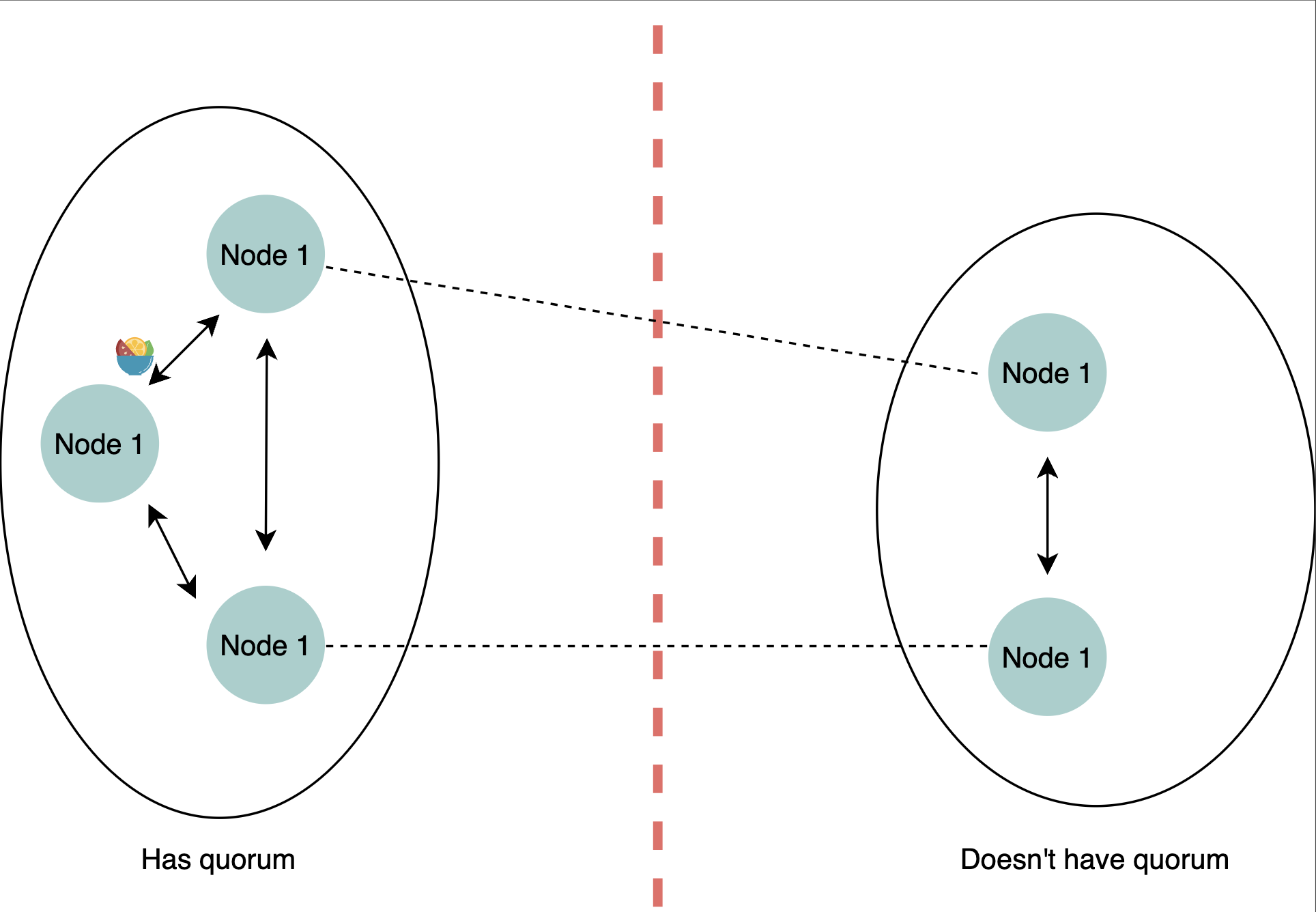
Quorum 应用于许多其他场景,例如:
- 分布式数据库: 在分布式数据库中,Quorum 用于确保数据的一致性。例如,在进行写操作时,必须获得 Quorum 个节点的确认,才能保证数据的一致性。
- 区块链: 在区块链中,Quorum 用于确保区块链的安全性。例如,在进行交易时,必须获得 Quorum 个节点的确认,才能保证交易的有效性。
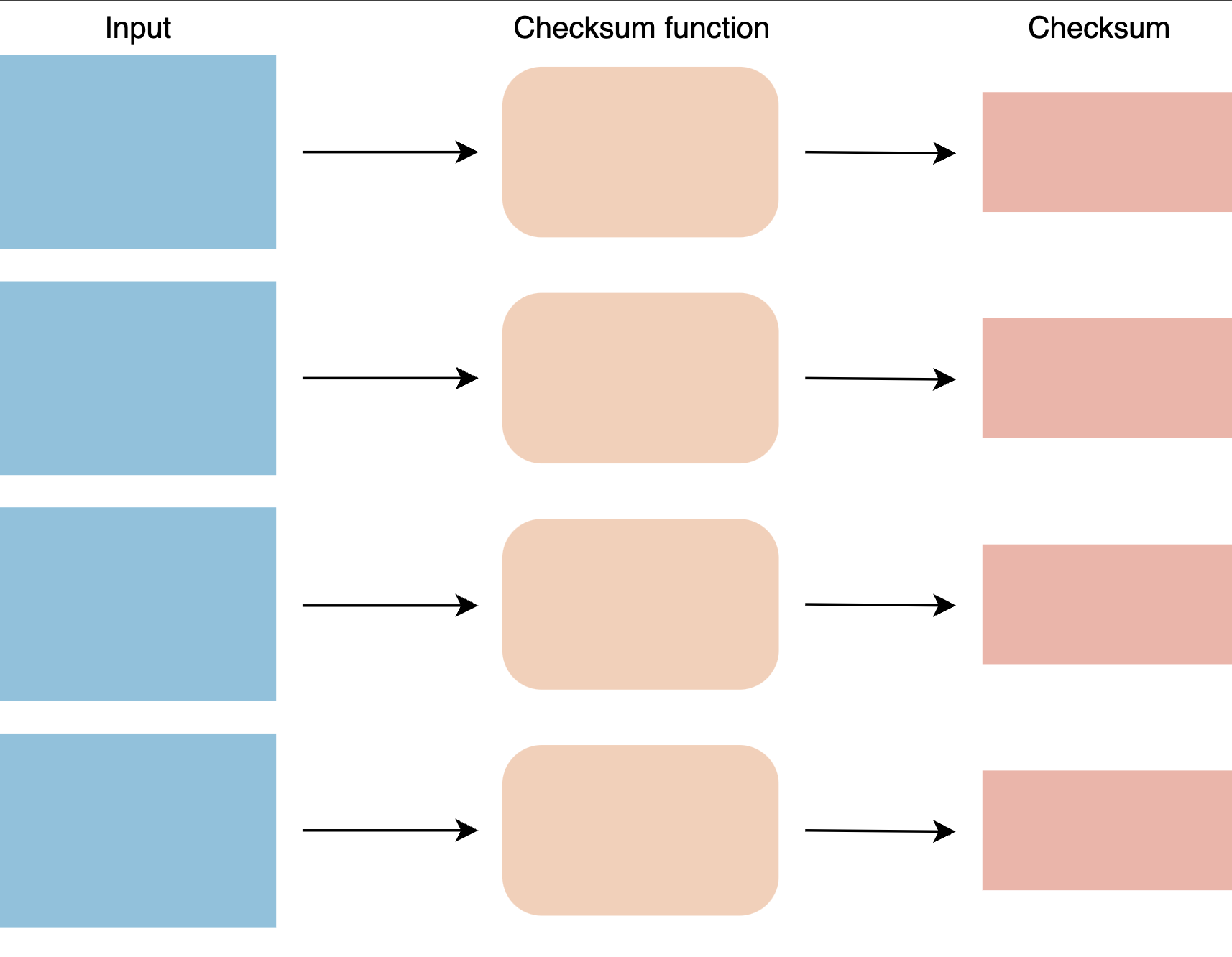
校验和 Checksum
当在分布式系统中的组件之间移动数据时,从节点获取的数据可能会损坏。这种损坏是由于存储设备、网络、软件等中的故障而发生的。当系统存储数据时,它计算数据的校验和并将校验和与数据一起存储。当客户端检索数据时,它会验证从服务器接收的数据是否与存储的校验和匹配。
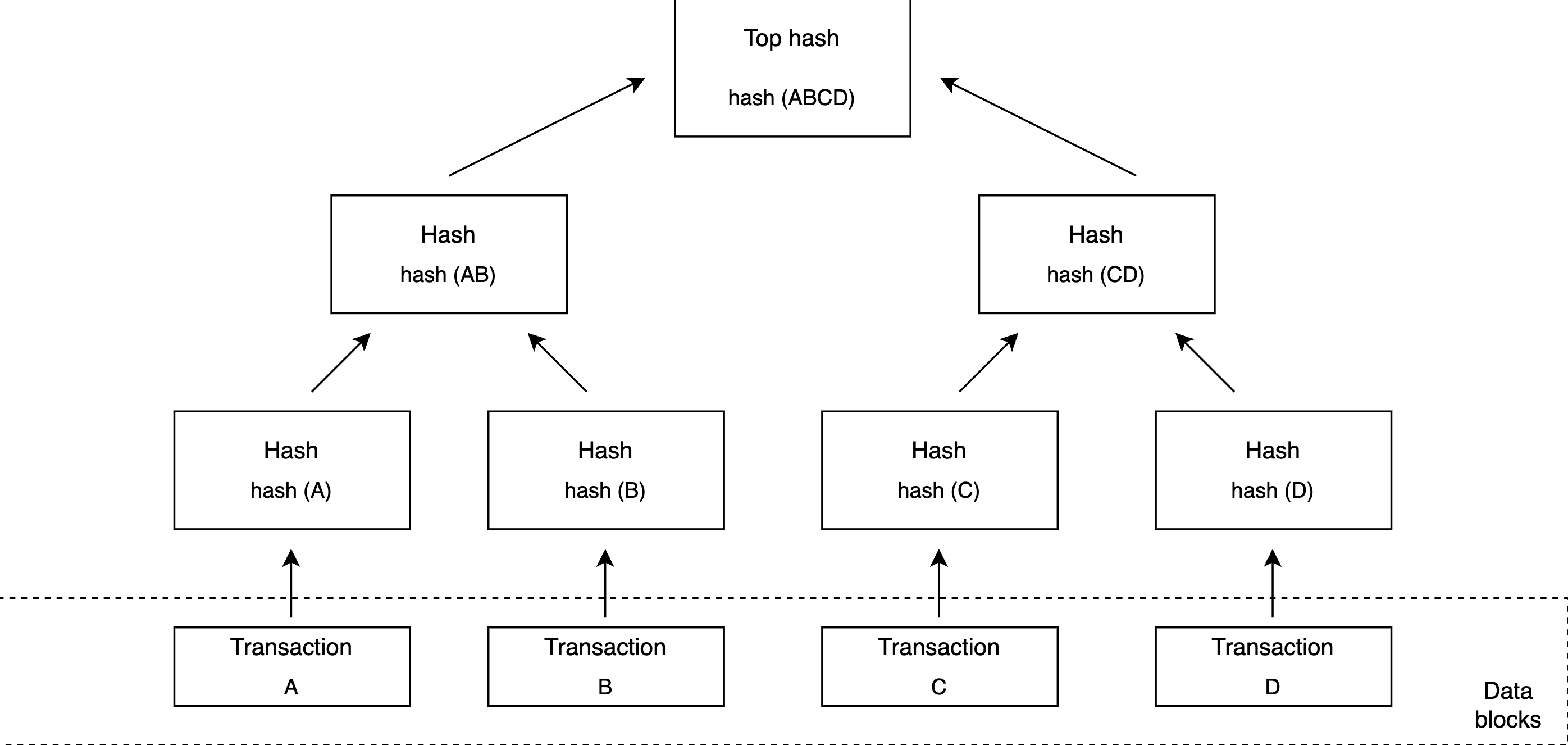
Merkle树
Merkle树是一个二进制哈希树,其中每个内部节点是它的两个孩子的哈希,每个叶节点是原始数据的一部分的哈希。副本可以包含大量数据。拆分整个范围来计算校验和进行比较是不太可行的,因为要传输的数据太多了。Merkle树使我们能够轻松地比较范围的副本。
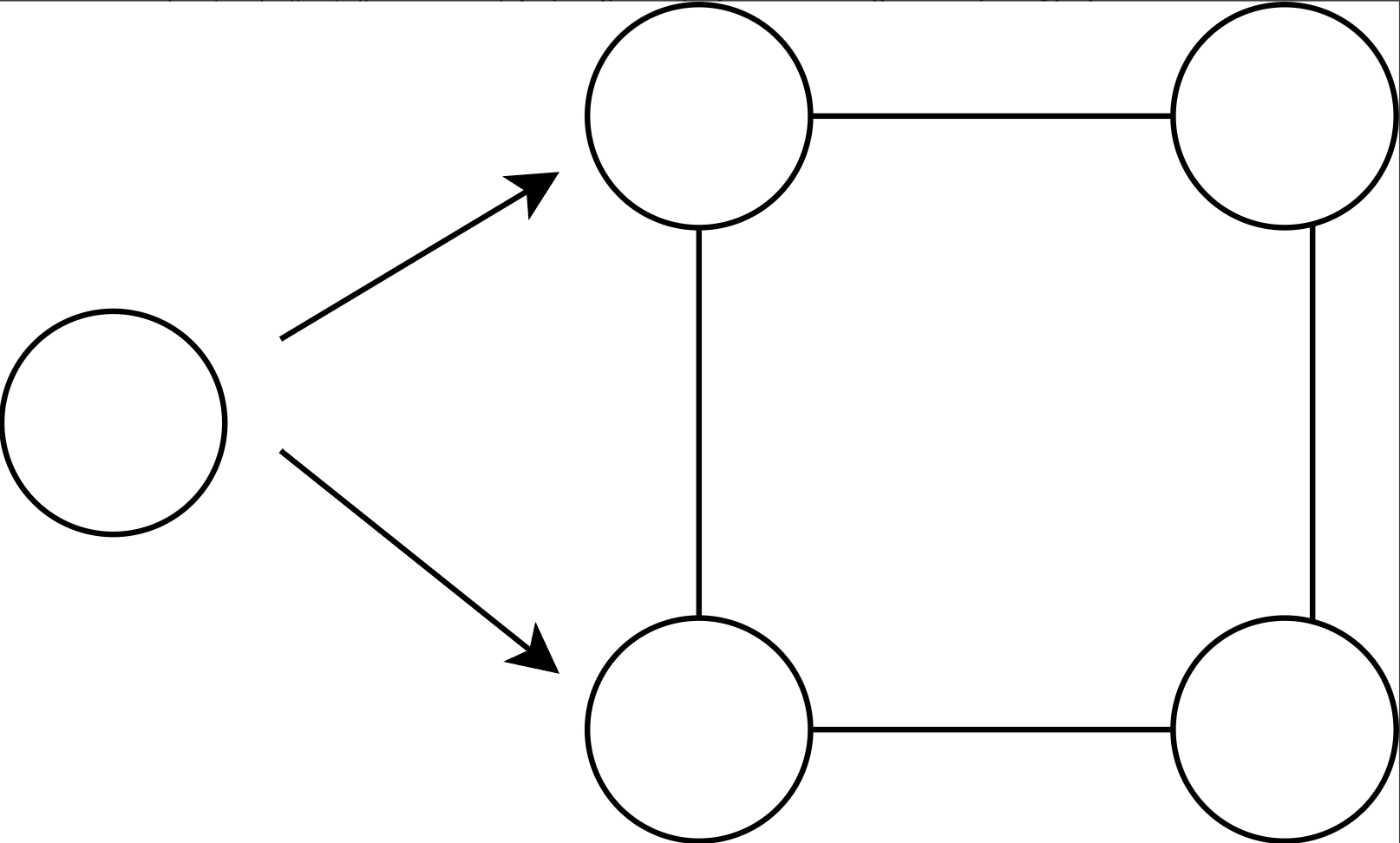
领导人选举 Leader election
Leader选举是指指定一个进程作为分布在多台计算机上的任务的组织者。它是一种算法,使整个网络中的每个节点都能识别出一个特定的节点作为任务的领导者。网络节点相互通信以确定它们中的哪一个将是领导者。Leader election提高了效率,简化了架构,减少了操作。
数据库 Databases
关系型数据库 Relational databases
关系数据库或SQL 数据库是结构化的。它们有预定义的模式,就像存储号码和地址的电话簿一样。 SQL 数据库以行和列的形式存储数据。每行包含有关单个实体的所有可用信息,每列包含所有单独的数据点。流行的 SQL 数据库包括:
- MySQL
- Oracle 甲骨文
- MS SQL Server 微软SQL服务器
- SQLite
- PostgreSQL
- MariaDB
MySQL
MySQL 是一个开源关系数据库管理系统 (RDBMS),它将数据存储在表和行中。它使用 SQL(结构化查询语言)来传输和访问数据,并使用SQL 连接来简化查询和关联。它遵循客户端-服务器架构并支持多线程。
PostgreSQL
PostgreSQL,也称为 Postgres,是一个强调可扩展性和 SQL 合规性的开源 RDBMS。 Postgres 使用 SQL 来访问和操作数据库。它使用自己的 SQL 版本,称为 PL/pgSQL,它可以执行比 SQL 更复杂的查询。 Postgres 事务遵循 ACID 原则。由于它具有关系结构,因此需要在创建时设计和配置整个模式。 Postgres 数据库使用外键,这使我们能够保持数据规范化。
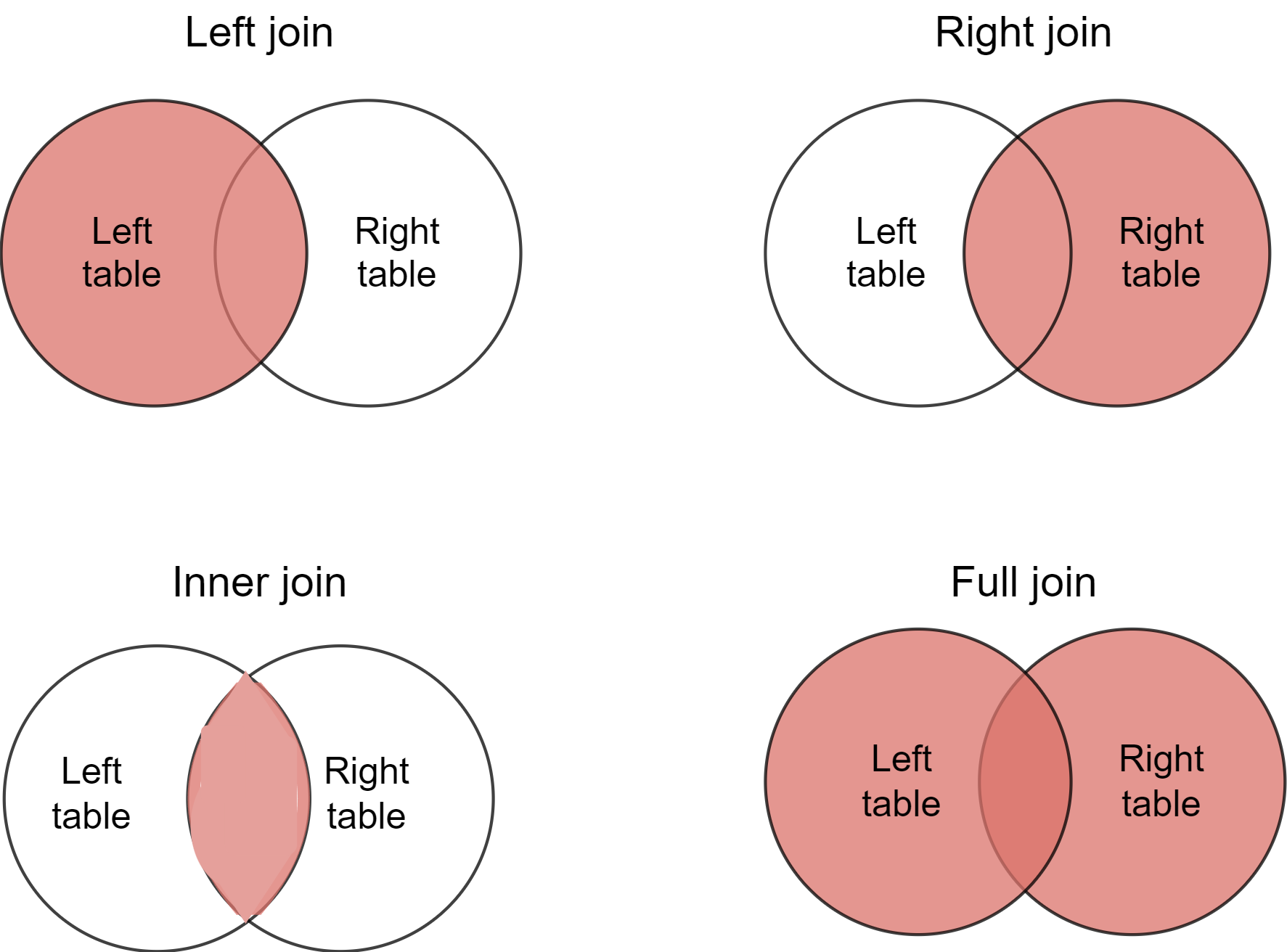
SQL 连接 SQL joins
SQL 连接允许我们同时访问两个或多个表中的信息。它们还使我们的数据库保持标准化,从而确保数据冗余度较低。当数据冗余度较低时,我们可以在删除或更新记录时减少应用程序中的数据异常量。
非关系型数据库 Non-relational databases
非关系数据库或非SQL 数据库是非结构化的。它们有一个动态模式,就像文件夹一样,用于存储从某人的地址和电话号码到他们的 Facebook 点赞和在线购物偏好等信息。 NoSQL 有不同类型。最常见的类型包括:
- Key-value stores, such as Redis and DynamoDB 键值存储,例如Redis和 DynamoDB
- Document databases, such as MongoDB and CouchDB 文档数据库,例如 MongoDB 和 CouchDB
- Wide-column databases, such as Cassandra and HBase 宽列数据库,例如 Cassandra 和 HBase
- Graph databases, such as Neo4J and InfiniteGraph 图数据库,例如 Neo4J 和 InfiniteGraph
MongoDB
MongoDB 是一种 NoSQL、非关系数据库管理系统 (DBMS),它使用文档而不是表或行来存储数据。该数据模型使得在单个数据库操作中操纵相关数据成为可能。 MongoDB 文档使用支持 JavaScript 的类似 JSON 的文档和文件。文档字段可能会有所不同,因此可以轻松地随着时间的推移更改结构。
如何选择数据库 How to choose a database
数据库是软件开发的基础。它们为各种规模和类型的建筑项目提供多种不同的用途。选择数据库结构时,考虑速度、可靠性和准确性非常重要。我们有可以保证数据可用性的关系型数据库,也有可以保证最终一致性的非关系型数据库。选择数据库结构时,考虑数据库基础知识非常重要,例如:
- ACID
- BASE
- SQL joins
- Normalization
- Persistence
- Etc.
数据库模式 Database schemas
数据库模式是表示数据库中数据存储的抽象设计。它们描述了给定数据库中数据的组织以及表之间的关系。您提前规划数据库模式,以便了解哪些组件是必需的以及它们如何相互连接。数据库模式不保存数据,而是描述数据的形状以及它与其他表或模型的关系。数据库中的条目是数据库模式的实例。
有两种主要的数据库模式类型定义模式的不同部分:逻辑和物理。
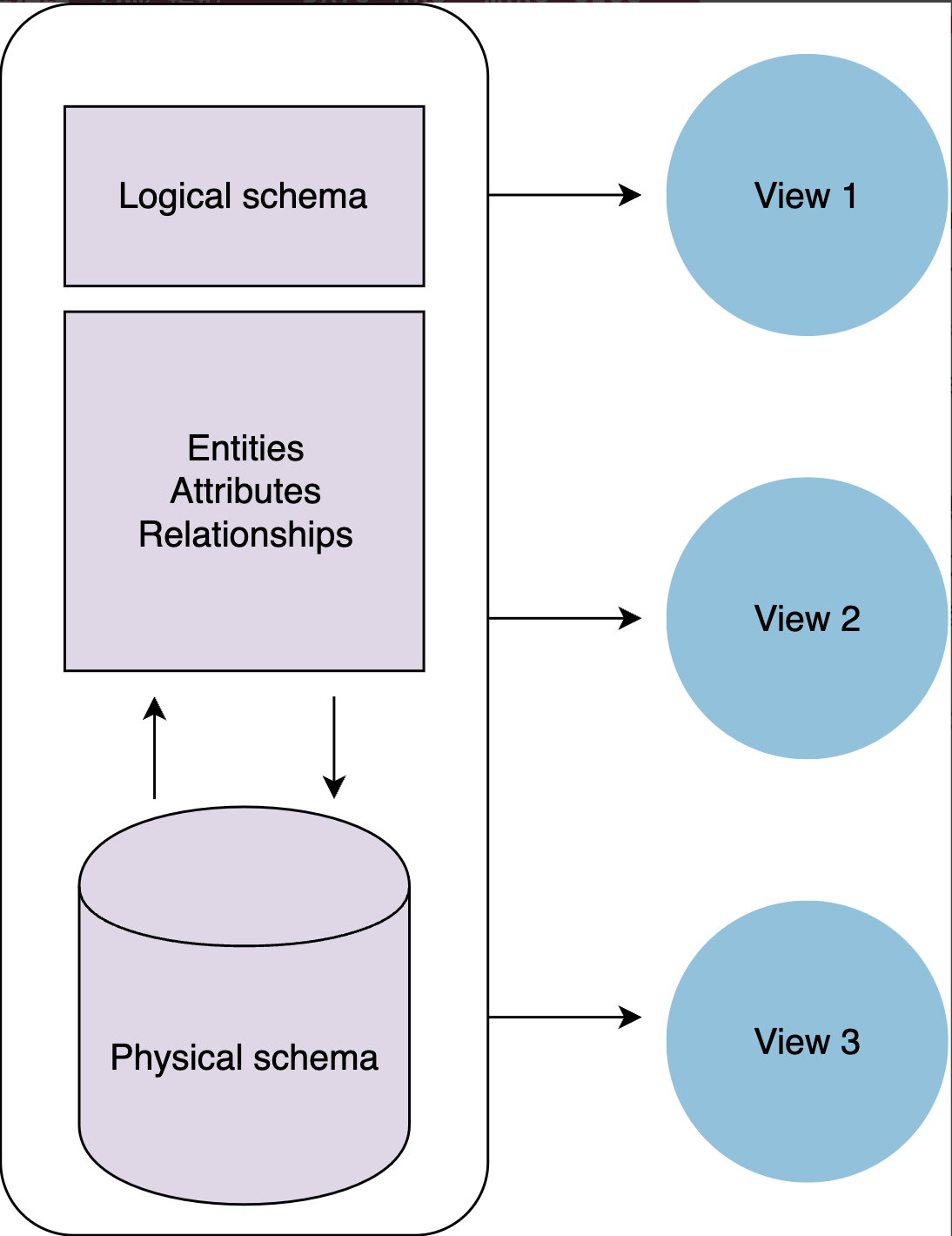
数据库模式包括:
- All important or relevant data 所有重要或相关数据
- Consistent formatting for all data entries 所有数据条目的格式一致
- Unique keys for all entries and database objects 所有条目和数据库对象的唯一键
- Each column in a table has a name and a data type 表中的每一列都有名称和数据类型
数据库模式的大小和复杂性取决于项目的大小。数据库模式的视觉风格允许您在进入代码之前正确构建数据库及其关系。规划数据库设计的过程称为数据建模。数据库模式对于设计 DBMS 和 RDBMS 非常重要。
数据库查询 Database queries
数据库查询是从数据库访问数据以操作或检索数据的请求。它与CRUD 操作关系最为密切。数据库查询允许我们使用响应查询而获得的信息执行逻辑。有许多不同的查询方法,从使用查询字符串到使用查询语言编写,再到使用 QBE(示例查询)(如 GraphQL)。
ACID 特性 ACID properties
为了维护数据库的完整性,所有事务都必须遵守ACID 属性。 ACID 是缩写词,代表原子性、一致性、隔离性和持久性。

- Atomicity: A transaction is an atomic unit. All of the instructions within a transaction will successfully execute, or none of them will execute. 原子性:事务是一个原子单元。事务中的所有指令都将成功执行,或者都不执行。
- Consistency: A database is initially in a consistent state, and it should remain consistent after every transaction. 一致性:数据库最初处于一致状态,并且在每次事务之后都应该保持一致。
- Isolation: If multiple transactions are running concurrently, they shouldn’t be affected by each other, meaning that the result should be the same as the result obtained if the transactions were running sequentially. 隔离性:如果多个事务并发运行,它们不应该互相影响,这意味着结果应该与事务顺序运行时获得的结果相同。
- Durability: Changes that have been committed to the database should remain, even in the event of a software or system failure. 持久性:即使发生软件或系统故障,已提交到数据库的更改也应保留。
数据库分片和分区 Database sharding and partitioning
对数据库进行分片时,您会对数据进行分区,以便将数据分为各种更小的、不同的块,称为分片。每个分片可以是一个表、一个 Postgres 模式或保存在单独数据库服务器实例上的不同物理数据库。数据库中的某些数据仍然存在于所有分片中,而某些数据仅出现在单个分片中。这两种情况可以称为垂直分片和水平分片。我们来看一个视觉效果:
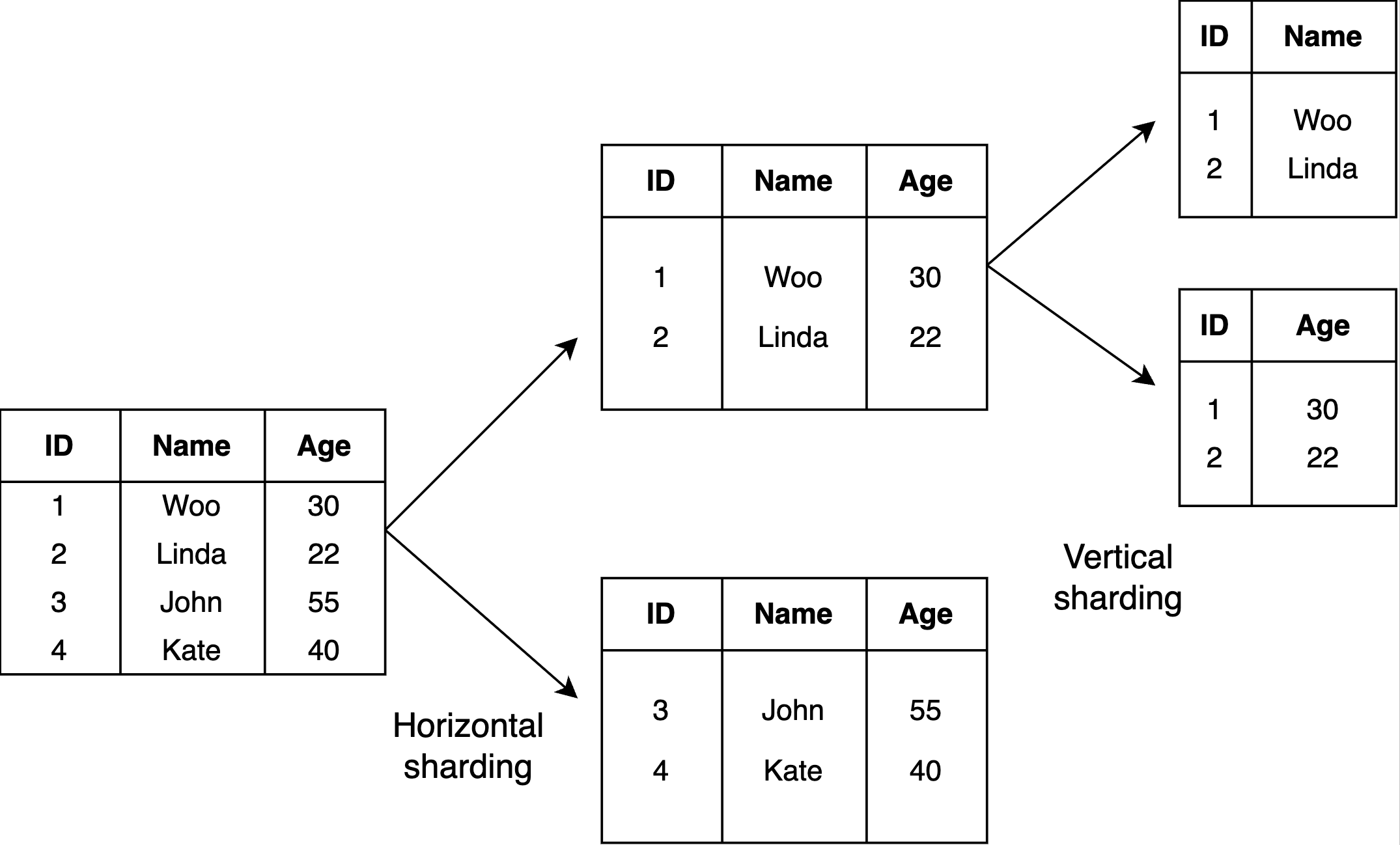
要对数据进行分片,您需要确定分片键来对数据进行分区。分片键可以是集合中每个文档中存在的索引字段或索引复合字段。没有确定分片键的通用规则。这一切都取决于您的应用程序。
分片允许您的应用程序进行更少的查询。当它收到请求时,应用程序知道将该请求路由到哪里。这意味着它必须查看更少的数据,而不是遍历整个数据库。分片可以提高应用程序的整体性能和可扩展性。
数据分区是一种将大数据库分解为更小的部分的技术。此过程允许我们将数据库拆分到多台机器上,以提高应用程序的性能、可用性、负载平衡和可管理性。
数据库索引 Database indexing
数据库索引使您可以更快、更轻松地搜索表并找到所需的行或列。可以使用数据库表的一列或多列创建索引,为快速随机查找和有序信息的高效访问提供基础。虽然索引极大地加快了数据检索速度,但由于其大小,它们通常会减慢数据插入和更新速度。
什么是分布式系统? What are distributed systems?
分布式系统使我们更容易以指数速度扩展我们的应用程序。许多顶级科技公司使用复杂的分布式系统来处理数十亿个请求并在不停机的情况下执行更新。分布式系统是一组计算机的集合,这些计算机一起工作为最终用户形成一台计算机。集合中的所有计算机共享相同的状态并同时运行。这些机器也可以独立发生故障,而不会影响整个系统。
分布式系统可能难以部署和维护,但它们提供了许多好处,包括:
- Scaling: Distributed systems allow you to scale horizontally to account for more traffic. 扩展:分布式系统允许您水平扩展以适应更多流量。
- Modular growth: There’s almost no cap on how much you can scale. 模块化增长:您可以扩展的程度几乎没有上限。
- Fault tolerance: Distributed systems are more fault-tolerant than single machines. 容错性:分布式系统比单机系统具有更高的容错性。
- Cost-effective: The initial cost is higher than traditional systems, but because of their capacity to scale, they quickly become more cost-effective. 成本效益:初始成本高于传统系统,但由于其扩展能力,它们很快就变得更具成本效益。
- Low latency: You can have a node in multiple locations, so traffic will hit the closest node. 低延迟:您可以在多个位置拥有一个节点,因此流量将到达最近的节点。
- Efficiency: Distributed systems break complex data into smaller pieces. 效率:分布式系统将复杂的数据分解成更小的部分。
- Parallelism: Distributed systems can be designed for parallelism, where multiple processors divide up a complex problem into smaller chunks. 并行性:分布式系统可以设计为并行性,其中多个处理器将复杂的问题划分为更小的块。
分布式系统故障 Distributed system failures
分布式系统可能会遇到多种类型的故障。四种基本类型的故障包括:
系统故障 System failure
系统故障是由于软件或硬件故障而发生的。系统故障通常会导致主存储器内容丢失,但辅助存储器仍然安全。每当系统出现故障时,处理器就无法执行任务,系统可能会重新启动或死机。
通讯介质故障 Communication medium failure
通信介质故障是由于通信链路故障或节点移动而发生的。
二级存储故障 Secondary storage failure
当辅助存储设备上的信息无法访问时,就会发生辅助存储故障。它可能是由许多不同的原因造成的,包括节点崩溃、介质上的污垢和奇偶校验错误。
方法失败 Method failure
方法失败通常会停止分布式系统并使其根本无法执行任何操作。系统可能会在方法失败期间进入死锁状态或发生保护违规。
分布式系统基础知识 Distributed system fundamentals
映射&归约 MapReduce
MapReduce是Google开发的一个框架,用于高效处理大量数据。 MapReduce 使用大量服务器进行数据管理和分发。该框架提供了对用户命令执行期间发生的底层进程的抽象。其中一些过程包括容错、分区数据和聚合数据。这些抽象允许用户专注于程序的更高级别逻辑,同时信任框架能够顺利地继续底层流程。
MapReduce的工作流程如下:

- Partitioning: The data is usually in the form of a big chunk. It’s necessary to begin by partitioning the data into smaller, more manageable pieces that can be efficiently handled by the map workers. 分区:数据通常以大块的形式存在。有必要首先将数据划分为更小、更易于管理的部分,以便Map Workers可以有效地处理这些部分。
- Map: Map workers receive the data in the form of a key-value pair. This data is processed by the map workers, according to the user-defined map function, to generate intermediate key-value pairs. Map :Map Workers 以键值对的形式接收数据。这些数据由Map Workers根据用户定义的map函数进行处理,以生成中间键值对。
- Intermediate files: The data is partitioned into R partitions (with R being the number of reduce workers). These files are buffered in the memory until the primary node forwards them to the reduce workers. 中间文件:数据被划分为R个分区( R是reduce workers的数量)。这些文件会缓冲在内存中,直到主节点将它们转发给reduce工作节点。
- Reduce: As soon as the reduce workers get the data stored in the buffer, they sort it accordingly and group data with the same keys. Reduce:一旦reduce workers获取存储在缓冲区中的数据,他们就会相应地对其进行排序,并使用相同的键对数据进行分组。
- Aggregate: The primary node is notified when the reduce workers are done with their tasks. In the end, the sorted data is aggregated together and R output files are generated for the user. 聚合:当reduce工作线程完成任务时,主节点会收到通知。最后,将排序后的数据聚合在一起,为用户生成R个输出文件。
无状态和有状态系统 Stateless and stateful systems
无状态和有状态系统是分布式系统世界中的重要概念。系统要么是无状态的,要么是有状态的。无状态系统不维护过去事件的状态。它根据我们提供给它的输入执行。有状态系统负责维护和改变状态。
无状态系统
- Web服务器:如Nginx或Apache,它们通常作为无状态系统运行,处理来自客户端的HTTP请求,而不保存任何会话状态。
- RESTful API:遵循REST原则的API通常是无状态的,每个请求都包含足够的信息以供服务器处理,而不需要依赖先前的请求。
有状态系统
- 数据库系统:如MySQL或MongoDB,它们保存客户端的数据并维护数据的状态,以便在后续查询中提供一致的结果。
- 会话管理:如Web应用中的用户登录会话,服务器需要保存用户的登录状态,以便在用户执行后续操作时识别用户。
Raft (分布式一致性算法)
Raft将复制状态机和相关命令复制日志的概念建立为first-class citizens,并默认支持多轮连续共识。它需要一组节点形成共识组,或者说 Raft 集群。其中每一个都可以处于以下三种状态之一:
- Leader 领导者
- Follower 追随者
- Candidate 候选人
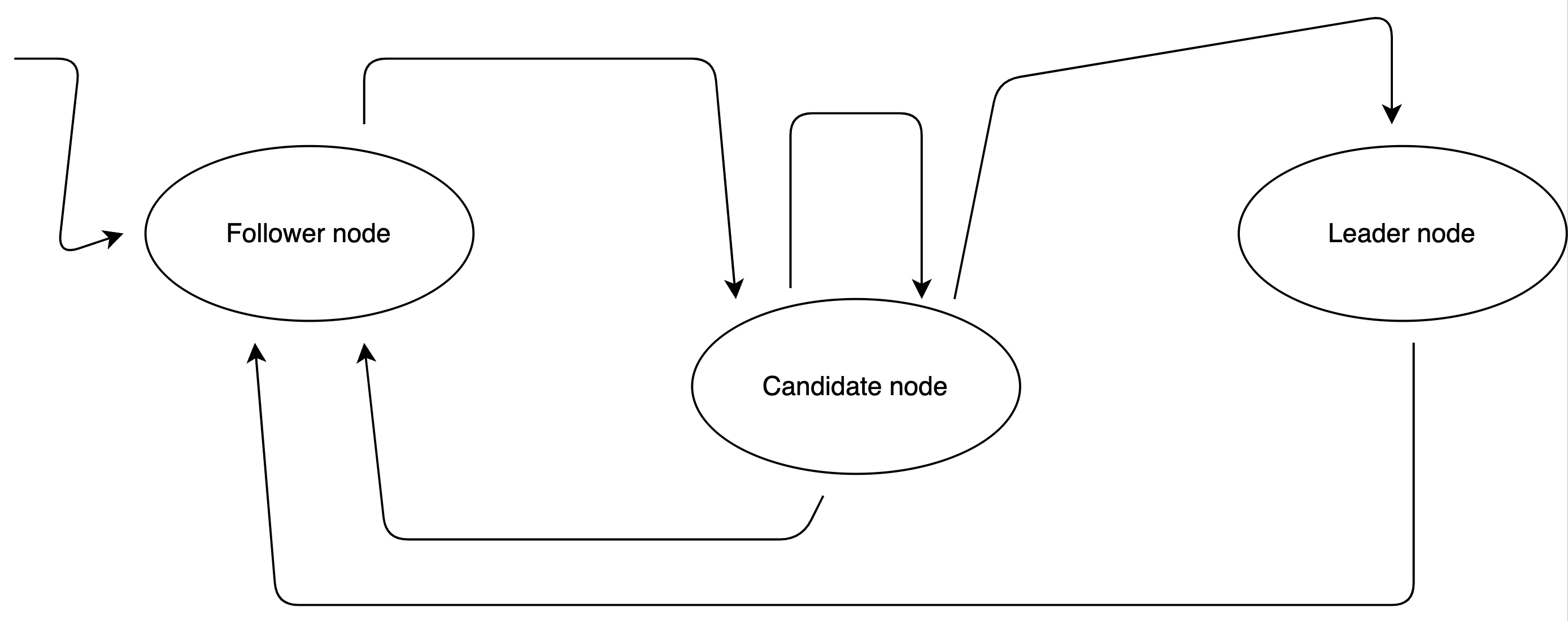
分布式一致性协议
分布式系统设计模式 Distributed system design patterns
设计模式为我们提供了构建适合特定用例的系统的方法。它们就像构建块一样,使我们能够从现有知识中提取知识,而不是从头开始每个系统。他们还创建了一组用于系统设计的标准模型,帮助其他开发人员了解他们的项目如何与给定系统交互。
创建型设计模式在构建新对象时提供了基线。结构模式定义了解决方案的整体结构。行为模式描述对象以及它们如何相互通信。分布式系统设计模式概述了不同节点如何相互通信、哪些节点处理特定任务以及各种任务的流程应该是什么样子的软件架构。
大多数分布式系统设计模式根据其使用的功能分为以下三类之一:
- Object communication: Describes the messaging protocols and permissions for different components of the system to communicate 对象通信:描述系统不同组件进行通信的消息传递协议和权限
- Security: Handles confidentiality, integrity, and availability concerns to ensure the system is secure from unauthorized access 安全性:处理机密性、完整性和可用性问题,以确保系统免受未经授权的访问
- Event-driven: Describes the production, detection, consumption, and response to system events 事件驱动:描述系统事件的产生、检测、消费和响应
可扩展的网络应用程序 Scalable web applications
DNS 和负载平衡 DNS and load balancing
DNS(即域名系统)通过将简单的域名映射到 IP 地址,避免了记住长 IP 地址来访问网站的情况。您可以为需要将用户流量分散到不同数据中心的不同集群的大型应用程序和系统设置 DNS 负载平衡。
负载平衡对于我们的扩展工作非常重要。它使我们能够随着流量的增加而有效地扩展并保持高可用性。负载平衡由负载平衡器执行,负载平衡器是充当反向代理的设备。他们负责使用不同的算法在多个服务器之间分配网络流量。流量分布有助于避免所有流量汇聚到单台机器或集群中的几台机器的风险。如果流量仅集中到几台机器,这将使它们超载并导致它们瘫痪。
负载均衡可以帮助我们避免这些问题。如果应用程序处理用户请求时服务器出现故障,负载均衡器会自动将未来的请求路由到正在运行的服务器。
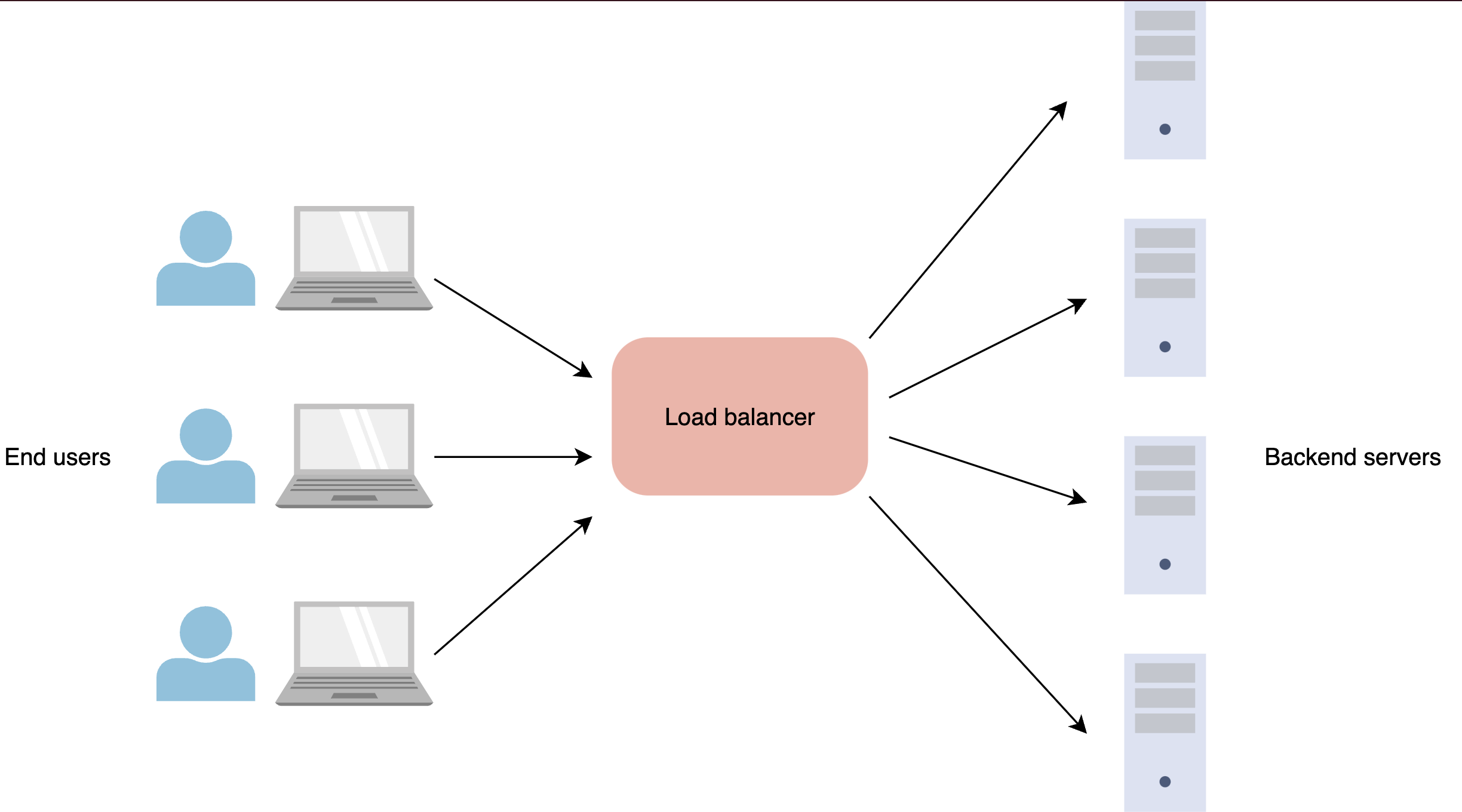
Load balancer 负载均衡器
N层应用程序 N-tier applications
N 层应用程序或分布式应用程序是涉及三个以上组件的应用程序。这些组件可以是:
- Caches 缓存
- Message queues 消息队列
- Load balancers 负载均衡器
- Search servers 搜索服务器
- Components involved in processing large amounts of data 涉及处理大量数据的组件
- Components running heterogeneous tech, commonly known as web services 运行异构技术的组件,通常称为 Web 服务
Instagram、Facebook 和 Uber 等大型应用程序是 n 层应用程序。
HTTP 和 REST HTTP and REST
HTTP 代表超文本传输协议。该协议规定了消息的格式、消息发送的方式和时间、适当的响应以及消息的解释方式。 HTTP 消息可以是请求,也可以是响应。 HTTP API 将端点公开为 API 网关,以便 HTTP 请求访问服务器。根据其目标用例,它们有多种形式,并且可以根据创建它们时使用的架构设计原则进一步分类。
REST 代表表述性状态转移。它是一种用于实现 Web 服务的软件架构风格。 REST 是一个规则集,定义了客户端和服务器之间共享数据的最佳实践,它强调组件的可扩展性和接口的简单性。 REST 应用程序使用 HTTP 方法,例如GET 、 POST 、 DELETE和PUT 。
REST API 是遵循 REST 架构原则的 API 实现。它们充当客户端和服务器之间通过 HTTP 进行通信的接口。 REST API 利用 HTTP 方法在客户端和服务器之间建立通信。 REST 还使服务器能够缓存响应,从而提高应用程序性能。
HTTP 和 REST 是系统设计中客户端-服务器通信的重要概念和考虑因素。
流处理 Stream processing
流处理是指专注于实时处理连续数据流的计算机编程架构。流行的流处理工具包括 Kafka、 Storm和 Flink。
缓存 Caching
缓存是用于临时存储数据以便快速访问的硬件或软件。缓存通常非常小,这使得它们具有成本效益且高效。它们由缓存客户端使用,例如 Web 浏览器、CPU、操作系统和 DNS 服务器。从缓存访问数据比从主内存或任何其他类型的存储访问数据要快得多。
什么是缓存?它是如何运作的?What is caching? How does it work?
假设客户端想要访问一些数据。首先,客户端可以检查数据是否存储在缓存中。如果他们找到数据,将立即返回给客户端。这称为缓存命中。如果数据未存储在缓存中,则会发生缓存未命中。当发生这种情况时,客户端从主存获取数据并将其存储在缓存中。
有不同类型的缓存策略:
缓存失效 Cache invalidation
缓存失效是计算机系统将缓存条目声明为“无效”并删除或替换它们的过程。此过程的基本目标是确保当客户端请求受影响的内容时,返回最新版本。定义了三种缓存失效方案:
直写式缓存 Write-through cache

写操作先失效并更新缓存,后写入DB
绕写式缓存 Write-around cache
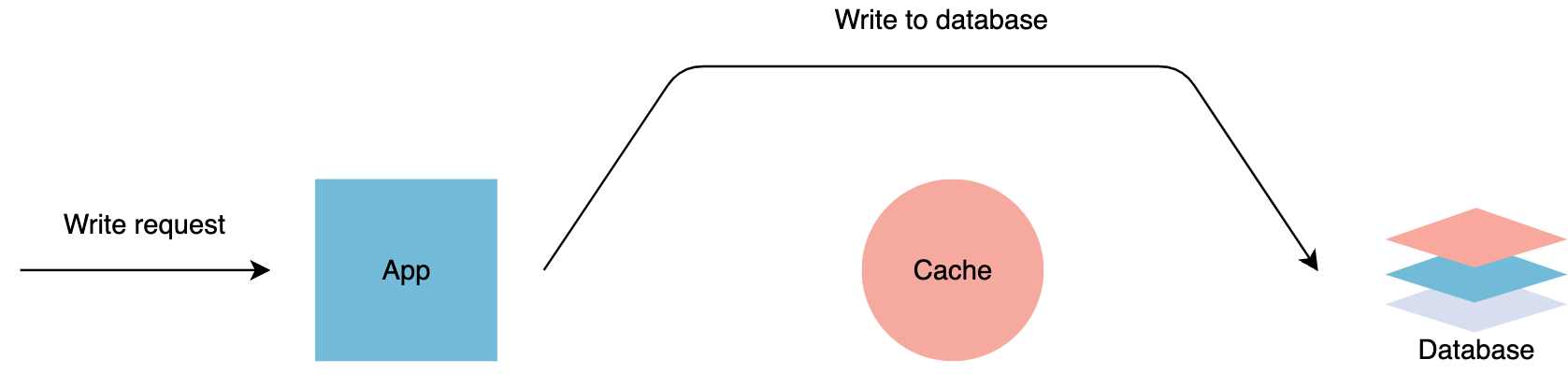
写操作直接失效缓存,并写入DB
回写式缓存 Write-back cache

写操作更新缓存后返回ack响应,并异步刷缓存进DB
缓存驱逐 Cache eviction
如果缓存有空间,数据就很容易插入。如果缓存已满,一些数据将被驱逐。什么被驱逐以及为什么被驱逐取决于所使用的驱逐政策。一些常用的缓存逐出策略包括:
- First in first out (FIFO): The cache evicts the first block accessed first without any regard to how often or how many times it was accessed before. 先进先出(FIFO) :缓存逐出最先访问的第一个块,而不考虑它之前被访问的频率或次数。
- Last in first out (LIFO): The cache evicts the block accessed most recently first without any regard to how often or how many times it was accessed before. 后进先出(LIFO) :缓存首先逐出最近访问的块,而不考虑它之前被访问的频率或次数。
- Least recently used (LRU): The cache evicts the least recently used items first. 最近最少使用 (LRU) :缓存首先逐出最近最少使用的项目。
- Most recently used (MRU): The cache evicts the most recently used items first. 最近使用的 (MRU) :缓存首先逐出最近使用的项目。
- Least frequently used (LFU): The cache counts how often an item is needed. The items that are used least frequently are evicted first. 最不频繁使用 (LFU) :缓存计算需要某个项目的频率。最不常用的物品首先被驱逐。
- Random replacement (RR): The cache randomly selects a candidate and evicts it. 随机替换(RR) :缓存随机选择一个候选者并将其驱逐。
机器学习和系统设计 Machine learning and System Design
机器学习 (ML) 应用程序和系统越来越受欢迎,并且在各个行业中得到越来越广泛的使用。随着这些机器学习应用程序和系统的不断成熟和扩展,我们需要开始更深入地思考如何设计和构建它们。机器学习系统设计是定义机器学习系统的软件架构、算法、基础设施和数据以满足特定要求的过程。
容器化和系统设计 Containerization and System Design

容器化是将软件代码及其依赖项打包,以创建可以在任何基础设施上运行的“容器”。我们可以将容器视为更轻量级的虚拟机 (VM) 版本,不需要自己的操作系统。主机上的所有容器共享该主机的操作系统,这可以释放大量系统资源。在 Docker 出现之前,容器化还不太容易实现。 Docker 是一个开源容器化平台,我们可以用它来构建和运行容器。 Docker 容器在应用层创建了一个抽象层。
Docker 经常与 Kubernetes 混淆,后者是另一种流行的容器化工具。这两种技术相辅相成,经常一起使用。 Docker 是一个容器化平台,而 Kubernetes 是一个容器化软件,可以让我们控制和管理容器和虚拟机。借助 Kubernetes,您可以运行 Docker 容器并管理容器化应用程序。容器被分组为 Pod,并且可以根据需要扩展和管理这些 Pod。
云和系统设计 The Cloud and System Design

云计算允许通过连接互联网的异地数据中心按需访问存储或开发平台等服务。数据中心由第三方公司或云提供商管理。云计算模型不仅解决了本地系统出现的问题,而且更具成本效益、可扩展性和便捷性。
不同的云提供商提供不同的云服务,例如存储、安全、访问管理等。云服务为您提供了能够设计和实施灵活高效的系统的工具。云服务的规模和复杂性各不相同,并且您可以利用多种云部署模型。不同的云系统架构包括:
- Multi-cloud 多云
- Hybrid cloud 混合云
- Single cloud 单云
- Public cloud 公有云
- Private cloud 私有云