1.背景
不知道大家有没有用Redis的Hash数据结构来缓存一种类的多个不同对象实体的经历,把不同对象的ID作为Hash的field,对象的JSON序列化字符串作为value。如果这个Hash里面的对象太多,且有部分对象过了一定时间后就不会再被访问到,这个时候我们是不是会想到要给其中某些field(后面暂且称之为子元素吧)给设置过期时间,不然的话,如果Hash里面的对象数量一直增长,将会造成Redis的内存爆炸。所以,怎么给Hash的子元素设置过期时间呢?
2.是否是伪需求
这时候有些同学就会说了,我直接把每一个field当做Redis的String类型的key,对象的JSON字符串作为String的value存不就可以了,这样不就可以针对每一个对象设置一个过期时间了。按理说,如果只要求设置过期时间,这样做是没问题的,而且这样做也最简单。但是如果你做过测试,你会发现同样数量的元素,用一个Hash结构存储和用若干个String结构存储,更节省内存。因为我们简单想一下,不管我们的Hash还是String类型的key,一般都会有个前缀,而用Hash定位一个元素只需要在Redis中存储一份这个前缀,但是用String就会导致不同的元素都要有这个前缀,不然你就无法根据前缀拼接ID来定位一个元素了。
所以给Hash里面的子元素设置过期时间的需求是存在的。
3.如何实现
方式一:我们可以使用Redis的ZSET数据结构来实现
下图是一个hash结构的数据,我们用hash里面的key表示id,value是实体类的JSON字符串:
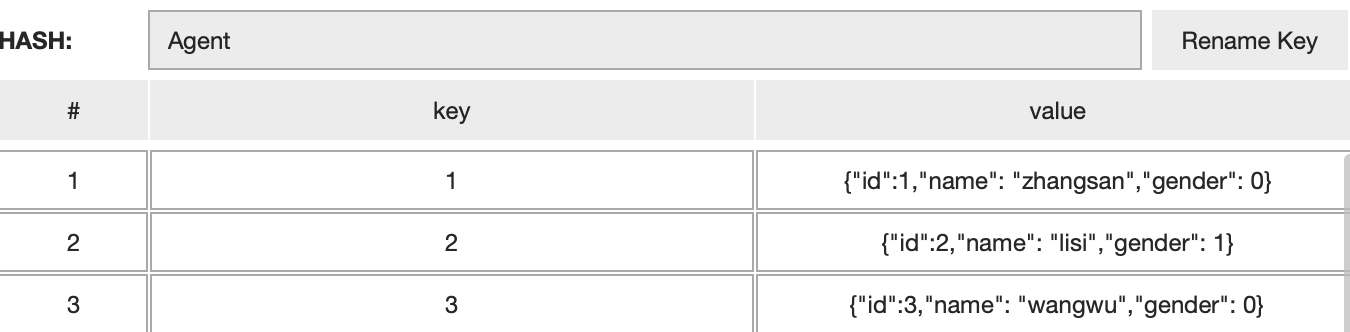
然后我们再每次往Agent这个hash结构存储数据的时候,顺便往以AgentExpire为key的ZSET数据结构存储一份数据,这个数据的key是id,value是过期时间戳,如下图所示:
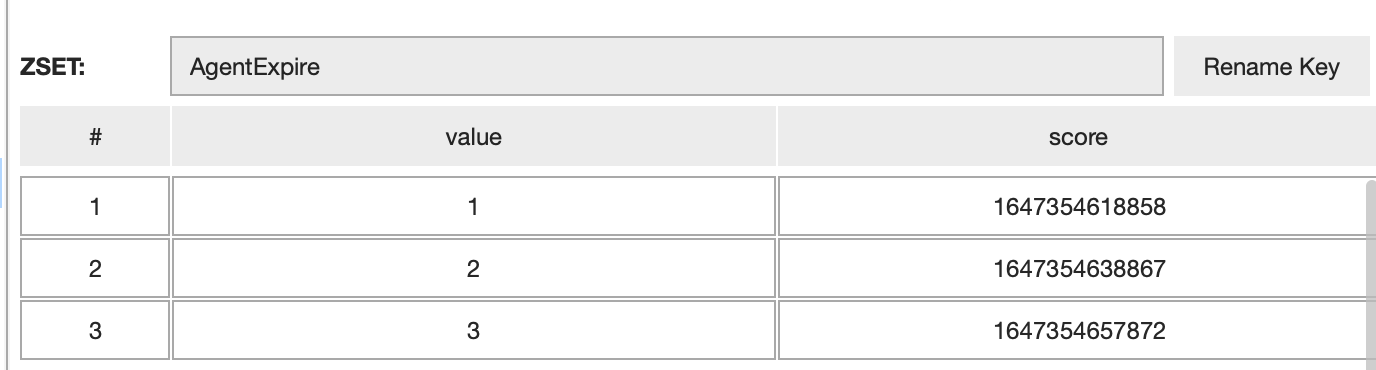
然后我们有个定时任务定时去扫描这个ZSET里面score小于当前时间的元素,也就是使用ZSET的rangeByScore命令:
long currentTimeMillis = System.currentTimeMillis();Set<String> expireKeys = redisTemplate.opsForZSet().rangeByScore("AgentExpire", 0, currentTimeMillis);
这样我们就能找出哪些过期的key,然后去hash里面删除对应的元素了。
这个定时任务的间隔决定了发现过期key的敏感度,假如定时任务一秒钟扫描一次,那么hash里面的某个key最多超过过期时间一秒就会被删除。
方式二:通过延时队列
我们在往hash存入一个元素之后,往延时队列推送一条数据,延时的时长就是过期时间,这样当我们从延时队列取出数据时,把hash里面相应id的元素删掉即可。关于延时队列的知识本文就不赘述了,网上有很多关于延时队列的文章。
4.RateLimiter分布式限流器应用实践
Github:https://github.com/oneone1995/blog/issues/13
一:简单使用
很简单,相信大家都看得懂。
public class Main {
public static void main(String[] args) throws InterruptedException {
RRateLimiter rateLimiter = createLimiter();
int allThreadNum = 20;
CountDownLatch latch = new CountDownLatch(allThreadNum);
long startTime = System.currentTimeMillis();
for (int i = 0; i < allThreadNum; i++) {
new Thread(() -> {
rateLimiter.acquire(1);
System.out.println(Thread.currentThread().getName());
latch.countDown();
}).start();
}
latch.await();
System.out.println("Elapsed " + (System.currentTimeMillis() - startTime));
}
public static RRateLimiter createLimiter() {
Config config = new Config();
config.useSingleServer()
.setTimeout(1000000)
.setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
RRateLimiter rateLimiter = redisson.getRateLimiter("myRateLimiter");
// 初始化
// 最大流速 = 每1秒钟产生1个令牌
rateLimiter.trySetRate(RateType.OVERALL, 1, 1, RateIntervalUnit.SECONDS);
return rateLimiter;
}
}
二:源码分析
重点关注这行代码
// 最大流速 = 每1秒钟产生1个令牌
rateLimiter.trySetRate(RateType.OVERALL, 1, 1, RateIntervalUnit.SECONDS);
-
源码
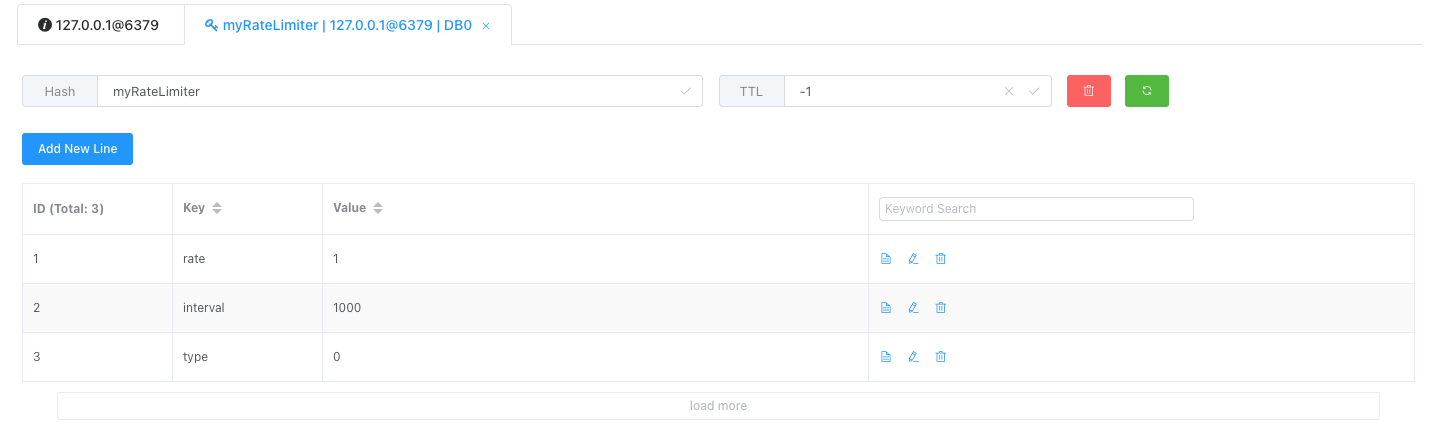
redis.call('hsetnx', KEYS[1], 'rate', ARGV[1]); redis.call('hsetnx', KEYS[1], 'interval', ARGV[2]); return redis.call('hsetnx', KEYS[1], 'type', ARGV[3]);对应Redis的数据结构:
-
RateType 限流类型 #type
public enum RateType { /** * Total rate for all RateLimiter instances */ OVERALL, /** * Total rate for all RateLimiter instances working with the same Redisson instance */ PER_CLIENT }-
OVERALL:应用所有Redis实例
-
PER_CLIENT:应用单个Redis实例
-
-
Rate 最大流速 #rate
-
RateInterval 限流频率,单位ms #interval
-
-
令牌生成 通过Demo的代码示例点进去,最后可以看到执行lua脚本拿令牌的代码在
org.redisson.RedissonRateLimiter#tryAcquireAsync(org.redisson.client.protocol.RedisCommand<T>, java.lang.Long)这个方法里,我把它的lua脚本拷出来写了注释-- 速率 local rate = redis.call("hget", KEYS[1], "rate") -- 时间区间(ms) local interval = redis.call("hget", KEYS[1], "interval") local type = redis.call("hget", KEYS[1], "type") assert(rate ~= false and interval ~= false and type ~= false, "RateLimiter is not initialized") -- {name}:value 分析后面的代码,这个key记录的是当前令牌桶中的令牌数 local valueName = KEYS[2] -- {name}:permits 这个key是一个zset,记录了请求的令牌数,score则为请求的时间戳 local permitsName = KEYS[4] -- 单机限流才会用到,集群模式不用关注 if type == "1" then valueName = KEYS[3] permitsName = KEYS[5] end -- 原版本有bug(https://github.com/redisson/redisson/issues/3197),最新版将这行代码提前了 -- rate为1 arg1这里是 请求的令牌数量(默认是1)。rate必须比请求的令牌数大 assert(tonumber(rate) >= tonumber(ARGV[1]), "Requested permits amount could not exceed defined rate") -- 第一次执行这里应该是null,会进到else分支 -- 第二次执行到这里由于else分支中已经放了valueName的值进去,所以第二次会进if分支 local currentValue = redis.call("get", valueName) if currentValue ~= false then -- 从第一次设的zset中取数据,范围是0 ~ (第二次请求时间戳 - 令牌生产的时间) -- 可以看到,如果第二次请求时间距离第一次请求时间很短(小于令牌产生的时间),那么这个差值将小于上一次请求的时间,取出来的将会是空列表。反之,能取出之前的请求信息 -- 这里作者将这个取出来的数据命名为expiredValues,可认为指的是过期的数据 local expiredValues = redis.call("zrangebyscore", permitsName, 0, tonumber(ARGV[2]) - interval) local released = 0 -- lua迭代器,遍历expiredValues,如果有值,那么released等于之前所有请求的令牌数之和,表示应该释放多少令牌 for i, v in ipairs(expiredValues) do local random, permits = struct.unpack("fI", v) released = released + permits end -- 没有过期请求的话,released还是0,这个if不会进,有过期请求才会进 if released > 0 then -- 移除zset中所有元素,重置周期 redis.call("zrem", permitsName, unpack(expiredValues)) currentValue = tonumber(currentValue) + released redis.call("set", valueName, currentValue) end -- 这里简单分析下上面这段代码: -- 1. 只有超过了1个令牌生产周期后的请求,expiredValues才会有值。 -- 2. 以rate为3举例,如果之前发生了两个请求那么现在released为2,currentValue为1 + 2 = 3 -- 以此可以看到,redisson的令牌桶放令牌操作是通过请求时间窗来做的,如果距离上一个请求的时间已经超过了一个令牌生产周期时间,那么令牌桶中的令牌应该得到重置,表示生产rate数量的令牌。 -- 如果当前令牌数 < 请求的令牌数 if tonumber(currentValue) < tonumber(ARGV[1]) then -- 从zset中找到距离当前时间最近的那个请求,也就是上一次放进去的请求信息 local nearest = redis.call('zrangebyscore', permitsName, '(' .. (tonumber(ARGV[2]) - interval), tonumber(ARGV[2]), 'withscores', 'limit', 0, 1); local random, permits = struct.unpack("fI", nearest[1]) -- 返回 上一次请求的时间戳 - (当前时间戳 - 令牌生成的时间间隔) 这个值表示还需要多久才能生产出足够的令牌 return tonumber(nearest[2]) - (tonumber(ARGV[2]) - interval) else -- 如果当前令牌数 ≥ 请求的令牌数,表示令牌够多,更新zset redis.call("zadd", permitsName, ARGV[2], struct.pack("fI", ARGV[3], ARGV[1])) -- valueName存的是当前总令牌数,-1表示取走一个 redis.call("decrby", valueName, ARGV[1]) return nil end else -- set一个key-value数据 记录当前限流器的令牌数 redis.call("set", valueName, rate) -- 建了一个以当前限流器名称相关的zset,并存入 以score为当前时间戳,以lua格式化字符串{当前时间戳为种子的随机数、请求的令牌数}为value的值。 -- struct.pack第一个参数表示格式字符串,f是浮点数、I是长整数。所以这个格式字符串表示的是把一个浮点数和长整数拼起来的结构体。我的理解就是往zset里记录了最后一次请求的时间戳和请求的令牌数 redis.call("zadd", permitsName, ARGV[2], struct.pack("fI", ARGV[3], ARGV[1])) -- 从总共的令牌数 减去 请求的令牌数。 redis.call("decrby", valueName, ARGV[1]) return nil end总结一下,redisson用了
zset来记录请求的信息,这样可以非常巧妙的通过比较score,也就是请求的时间戳,来判断当前请求距离上一个请求有没有超过一个令牌生产周期。如果超过了,则说明令牌桶中的令牌需要生产,之前用掉了多少个就生产多少个,而之前用掉了多少个令牌的信息也在zset中保存了。然后比较当前令牌桶中令牌的数量,如果足够多就返回了,如果不够多则返回到下一个令牌生产还需要多少时间。这个返回值特别重要。
接下来就是回到java代码,各个API入口点进去,最后都会调到
org.redisson.RedissonRateLimiter#tryAcquireAsync(long, org.redisson.misc.RPromise<java.lang.Boolean>, long)这个方法。我也拷出来做了简单的注释。private void tryAcquireAsync(long permits, RPromise<Boolean> promise, long timeoutInMillis) { long s = System.currentTimeMillis(); RFuture<Long> future = tryAcquireAsync(RedisCommands.EVAL_LONG, permits); future.onComplete((delay, e) -> { if (e != null) { promise.tryFailure(e); return; } if (delay == null) { //delay就是lua返回的 还需要多久才会有令牌 promise.trySuccess(true); return; } //没有手动设置超时时间的逻辑 if (timeoutInMillis == -1) { //延迟delay时间后重新执行一次拿令牌的动作 commandExecutor.getConnectionManager().getGroup().schedule(() -> { tryAcquireAsync(permits, promise, timeoutInMillis); }, delay, TimeUnit.MILLISECONDS); return; } //el 请求redis拿令牌的耗时 long el = System.currentTimeMillis() - s; //如果设置了超时时间,那么应该减去拿令牌的耗时 long remains = timeoutInMillis - el; if (remains <= 0) { //如果那令牌的时间比设置的超时时间还要大的话直接就false了 promise.trySuccess(false); return; } //比如设置的的超时时间为1s,delay为1500ms,那么1s后告知失败 if (remains < delay) { commandExecutor.getConnectionManager().getGroup().schedule(() -> { promise.trySuccess(false); }, remains, TimeUnit.MILLISECONDS); } else { long start = System.currentTimeMillis(); commandExecutor.getConnectionManager().getGroup().schedule(() -> { //因为这里是异步的,所以真正再次拿令牌之前再检查一下过去了多久时间。如果过去的时间比设置的超时时间大的话,直接false long elapsed = System.currentTimeMillis() - start; if (remains <= elapsed) { promise.trySuccess(false); return; } //再次拿令牌 tryAcquireAsync(permits, promise, remains - elapsed); }, delay, TimeUnit.MILLISECONDS); } }); }再次总结一下,Java客户端拿到redis返回的
下一个令牌生产完成还需要多少时间,也就是delay字段。如果这个delay为null,则表示成功获得令牌,如果没拿到,则过delay时间后通过异步线程再次发起拿令牌的动作。这里也可以看到,redisson的RateLimiter是非公平的,多个线程同时拿不到令牌的话并不保证先请求的会先拿到令牌。这里对应Redis的数据结构
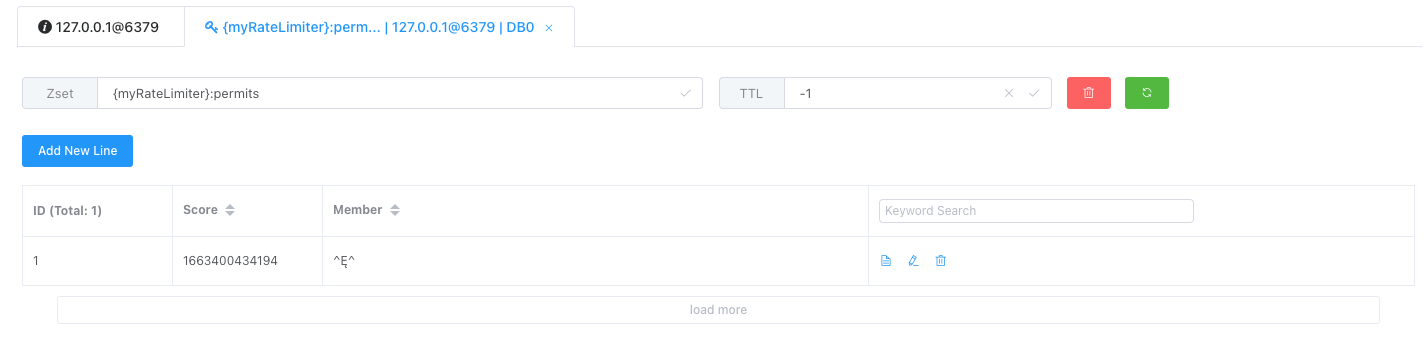
是不是很像用zset结构实现过期,score存储的是时间戳,member存储需要过期的值